Reliability Engineering · Special Topic
贝叶斯方法与可靠性工程
Bayesian Methods for Reliability Engineering — A Lecture Series
本讲义系统讲解贝叶斯方法及其在可靠性工程中的应用:以「先验—似然—后验」为主线,从概率的三种解释出发,依次建立贝叶斯定理、参数估计、共轭先验、混合模型与 EM、模型选择、朴素贝叶斯分类,直至贝叶斯网络;并贯穿诊断检测、挑战者号 O 型圈、发动机故障诊断、无人机风险评估等工业案例,强调「数据与工程经验的融合建模」。
第一部分
贝叶斯方法基础
从经典可靠性到现代方法 · 概率三学派 · 贝叶斯定理(第 1–2 章)
第二部分
贝叶斯推断与估计
先验/似然/后验 · 三种估计方法 · Beta–Binomial 共轭(第 3–6 章)
第三部分
混合模型与 EM 算法
模型复杂度 · 高斯混合模型 · EM 算法 · 模型选择 · 诊断检测(第 7–11 章)
第四部分
贝叶斯分类器与网络
朴素贝叶斯分类器 · 共轭先验 · 挑战者号案例 · 贝叶斯网络(第 12–16 章)
本教程基于中山大学先进制造学院 2025–2026 学年研究生课程《可靠性与人工智能专题》中「贝叶斯方法与可靠性」专题的课堂实录整理而成。课程横跨三周、共计六个课时,自概率论的基础讲起,循序而入贝叶斯定理、混合模型与 EM 算法、朴素贝叶斯分类器、共轭先验,以至贝叶斯网络等核心主题。
与寻常讲义不同,本教程着意保留授课现场的讲解肌理——那些临场的比喻、随手写下的推演,以及一个例子如何被一层层剥开的过程。机床车间里一缕焦糊味怎样改写了对故障的判断、一纸「准确率百分之九十九」的检测何以暗藏着假阳性的悖论、一枚来历不明的硬币如何在十次抛掷之间更新人的信念、又如何凭身高体重之类的蛛丝马迹去判别一名中山大学学生的性别,以及挑战者号航天飞机在三十一华氏度的清晨为何几乎注定失事——这些工业与生活场景中的实例,皆在书中尽量原样呈现。窃以为,方法之「形」易于传授,而方法背后的「势」——它在何处发力、为何如此发力——往往恰恰藏在这些现场的细节里。
全书循授课之序,分为四个部分:
一、贝叶斯方法基础 ——从经典可靠性走向现代方法,概率的三种学派,贝叶斯定理。二、贝叶斯推断与估计 ——先验、似然与后验,三种估计方法,Beta–Binomial 共轭。三、混合模型与 EM 算法 ——模型复杂度,高斯混合模型,期望最大化算法,以及诊断检测中的基率谬误。四、贝叶斯分类器与网络 ——朴素贝叶斯分类器,共轭先验,挑战者号案例,贝叶斯网络。
需要郑重说明的是:这份文字,乃由课堂讲义与备课记录整理而来,本非成熟著述。讲台上的话语贵在生动,落于纸面却难免疏漏与未尽规范之处;其间的取舍、补订与推演,皆系一己之力勉为之,挂一漏万,势所难免。我愿先以此粗稿就教于同道与后学,待来日从容修订,使之渐臻完善。倘读者能于其中得一二启发,体味到贝叶斯方法那种「以旧知纳新证、于不确定中求决断」的朴素而深远的意趣,便是对这番整理最好的回报了。
冯建设
中山大学 · 先进制造学院
2026 年 6 月
目录 Contents 前言 Preface
第一部分 · 贝叶斯方法基础
第 1 章 概率的三种解释:经典、频率与主观
第 2 章 条件概率、全概率与贝叶斯定理
第二部分 · 贝叶斯推断与估计
第 3 章 先验、似然、后验:机床诊断与抛硬币
第 4 章 贝叶斯的三种用途:推断、学习、估计
第 5 章 参数估计三法:MLE、MAP 与贝叶斯估计
第 6 章 共轭先验与 Beta 分布:从一枚硬币说起
第三部分 · 混合模型与 EM 算法
第 7 章 模型复杂度与分段建模
第 8 章 混合模型与高斯混合模型(GMM)
第 9 章 EM 算法(期望最大化)
第 10 章 模型选择:AIC 与 BIC
第 11 章 诊断检测与基率谬误:HIV 检测案例
第四部分 · 贝叶斯分类器与网络
第 12 章 贝叶斯分类与朴素贝叶斯分类器
第 13 章 可靠性案例:挑战者号 O 型圈灾难
第 14 章 共轭先验:共轭族与可靠性应用
第 15 章 贝叶斯网络:因果网络、d-分离与链式法则
第 16 章 贝叶斯网络的可靠性工程应用案例
附录
附录 作业集、参考文献与联系方式
I
PART ONE
第一部分 贝叶斯方法基础
Foundations of Bayesian Methods
从经典可靠性走向现代方法,概率的三种学派,贝叶斯定理。
第 1 章 概率的三种解释 经典 · 频率 · 主观 第 2 章 条件概率、全概率与贝叶斯定理 三块基石
第 1 章 概率的三种解释:经典、频率与主观从掷骰子的「等可能」假设,到「把经验注入模型」的贝叶斯世界观
1.0 为什么从这里讲起
前面整门可靠性课程,我们学的是经典方法论 :可靠性框图、故障树分析(FTA )、失效模式与影响分析(FMEA )。这些方法有一个共同的前提——系统结构是清晰的、因果是确定的 :从顶事件往下,每个节点的关系明确,每个底事件还服从一个很强的假设(指数分布、泊松分布、威布尔分布)。
但现代工程场景往往不这么「听话」:
因果是「软」的 。$A$ 与 $B$ 之间未必有「$A$ 必然推出 $B$」的强因果,而常常是一种带不确定性的关联。系统比想象的复杂 。真实系统的节点数、耦合关系远超教科书里 3–5 个节点的小例子。
从现在开始,我们转向一套更现代、也更有探索空间的方法,看它如何与可靠性——以及更广义的可靠性(含故障诊断 与健康预测 )——结合。整个专题课程包含贝叶斯方法、故障诊断与健康预测、蒙特卡洛分析三大方向,本教程聚焦其中的贝叶斯方法 。
◆ 评注
经典概率依赖「等可能」这一前提,而该前提本身往往难以验证:即便是骰子的制造者,也无法直接确证六个面严格等概率。正是这一困难,引出了频率学派与贝叶斯方法——本教程的主题。
1.1 经典概率(Classical Probability)
◆ 定义
若一个随机试验有 $n$ 个等可能 的结果,其中 $m$ 个有利于事件 $A$,则事件 $A$ 的概率为
$$ P(A)=\frac{m}{n}. \tag{1.1}$$
例(掷骰子)。 求「奇数面朝上」的概率:样本空间有 $\{1,2,3,4,5,6\}$ 共 6 个等可能结果,有利结果为 $\{1,3,5\}$ 共 3 个,故 $P=\tfrac{3}{6}=50\%$。
这个定义自帕斯卡时代沿用至今,简洁而有力。但它依赖一个极强的假设 :六个面「等可能」。一旦有人递给你一颗来历不明的骰子 (可能灌了铅),等可能假设就崩塌了——而经典概率本身无法验证 这个前提。这正是其它两种解释登场的原因。
1.2 频率学派概率(Frequentist Probability)
◆ 定义
若试验可重复进行,则事件 $A$ 的概率是其发生次数 $m$ 与总试验次数 $n$ 之比,在试验次数趋于无穷时的极限:
$$ P(A)=\lim_{n\to\infty}\frac{m}{n}. \tag{1.2}$$
面对那颗来历不明的骰子,频率学派说:「我不管它是什么骰子,我掷它足够多次。」 把每一面出现的频率画出来,你会看到它在波动中收敛 到某个稳定值——这与有限元里的 converge 、与人工智能训练中的「收敛」是同一回事:观察一个有界的、逐渐趋于特定值的过程。
▶ 工程例子:蒲丰投针(Buffon's Needle)估计 π
地面画一组间距为 $d$ 的平行线,把长度为 $\ell$ 的针随机投下 $N$ 次,记针与线相交 $H$ 次。当 $\ell\le d$ 时相交概率为 $P=\dfrac{2\ell}{\pi d}$,于是
$$ \pi \approx \frac{2\ell N}{d\,H}. $$
这是一个用「重复试验的频率」去逼近一个确定常数的典范——也正是蒙特卡洛方法 的思想源头:重复很多次,找到稳定的统计规律。建议课后用几十行代码亲手实现一次。
频率学派的局限 :它无法把已有经验融进来 。如果你是骰子厂的老板,难道每造一颗骰子都要掷一万次来验证它均匀吗?我们明明拥有历史数据、设计知识、专家判断——频率学派却没有为它们留下入口。
1.3 主观概率 / 贝叶斯概率(Subjective Probability)
◆ 定义
事件 $A$ 的概率是某个人基于个人经验、知识或直觉 给出的主观评估,又称贝叶斯概率 。
贝叶斯的世界观是:先基于知识给出一个猜测(先验),再用当前观测去更新它(得到后验)。 这恰好为「数据 + 经验」的融合提供了天然入口:
把你以往的认知、历史数据、专家意见,统统编码成先验 ;做实验、做观测得到的,就是数据 ;用数据去更新先验,得到与时俱进的后验 。
—— 这正是后续所有章节的主旋律
◆ 三种解释的对照(以「抛 10 次、出现 7 次正面」为例)
学派 对「正面概率」的回答 会随观测更新吗
经典概率 先验地认为 $0.5$(等可能) 不更新 频率学派 $m/n = 7/10 = 0.7$ 仅由频率决定 贝叶斯 先假设一个分布,再据观测持续更新 ,给出一个分布 而非单点 会,且具时效性
◆ 本章要点
经典概率靠「等可能」枚举,频率学派靠「重复试验取极限」,主观/贝叶斯靠「先验 + 观测更新」。
贝叶斯的独特价值:它是把经验知识与观测数据融合建模的天然框架 ——这对「数据稀少但工程经验丰富」的可靠性问题尤其关键。
贝叶斯给出的是一个分布 ,能持续更新,因而天然具备「自主学习」的能力。
第 2 章 条件概率、全概率与贝叶斯定理三块基石,搭起「用观测更新信念」的完整通路
本章把贝叶斯定理的三块基石——条件概率、全概率公式、贝叶斯定理——一次性串起来。它们你在本科都学过,这里的目的不是重新证明,而是将它们组织成「先验 → 似然 → 后验」的统一形式 ,为后续内容奠定基础。
2.1 条件概率(Conditional Probability)
◆ 定义
在事件 $B$ 已发生的条件下,事件 $A$ 发生的概率为
$$ P(A\mid B)=\frac{P(A\cap B)}{P(B)}. \tag{2.1}$$
其几何直观:$B$ 发生后,整个样本空间 $S$ 收缩为 $B$ ;此时 $A$ 能发生的部分只剩 $A\cap B$,再用 $B$ 的概率归一化。
S
A
B
A∩B
图 2.1 条件概率的几何直观。事件 $B$ 发生后,样本空间收缩为 $B$(绿圆);在这个新空间里 $A$ 能发生的部分只剩交集 $A\cap B$(金色),故 $P(A\mid B)=\dfrac{P(A\cap B)}{P(B)}$。
▶ 生活直觉:早上要不要带伞
事件 $A$=「两小时后下雨」,事件 $B$=「此刻的天象」。你绝不是每天早上抛硬币 决定带不带伞——你看天:$B$=乌云密布时 $P(A\mid B)$ 很大,$B$=晴空万里时 $P(A\mid B)$ 很小。这说明 $A$ 与 $B$ 不独立 ,$B$ 的取值会改变 $A$ 的概率。这正是条件概率刻画的东西,也是你每天都在用的推理。
2.2 全概率公式(Theorem of Total Probability)
设 $B_1,B_2,\dots,B_n$ 是样本空间 $S$ 的一组划分——它们两两互斥 (mutually exclusive )且完全穷尽 (其并集覆盖整个样本空间 $S$);二者共同保证 $\sum_i P(B_i)=1$。这正是我们在故障树分析里强调过的 MECE 原则 (Mutually Exclusive, Collectively Exhaustive ):不重、不漏。
◆ 全概率公式
对任意事件 $A$:
$$ P(A)=\sum_{i=1}^{n}P(A\cap B_i)=\sum_{i=1}^{n}P(A\mid B_i)\,P(B_i). \tag{2.2}$$
直观理解:既然 $\{B_i\}$ 铺满了整个空间,那么 $A$ 发生的总概率,就是「在每一块 $B_i$ 上 $A$ 发生的概率」按 $B_i$ 的权重加起来。例如把「当前天气」划分成 $B_1$=乌云、$B_2$=晴空,则下雨的总概率由这两种天气下的下雨概率加权而成。划分成 2 块还是 10 块,本质一样。
2.3 贝叶斯定理(Bayes' Theorem)
现在把问题倒过来 问:我已经知道 $A$ 发生了,那么某个特定的 $B_i$ 发生的概率是多少?由条件概率定义,$P(B_i\mid A)=\dfrac{P(B_i\cap A)}{P(A)}$,分子用 $P(A\mid B_i)P(B_i)$ 替换、分母用全概率公式 (2.2) 展开,即得:
◆ 贝叶斯定理
$$ P(B_i\mid A)=\frac{P(B_i\cap A)}{P(A)}=\frac{P(A\mid B_i)\,P(B_i)}{\displaystyle\sum_{j=1}^{n}P(A\mid B_j)\,P(B_j)}. \tag{2.3}$$
◆ 给每一项起个名字(全书通用)
这是整门课最重要的一张图 。式 (2.3) 中:
$P(B_i)$ ——先验 (Prior ):你对 $B_i$ 的既有认知 / 信念。
$P(A\mid B_i)$ ——似然 (Likelihood ):在 $B_i$ 成立时、观测到 $A$ 的可能性。
$P(B_i\mid A)$ ——后验 (Posterior ):看到证据 $A$ 之后,对 $B_i$ 更新后的信念。
分母 $P(A)=\sum_j P(A\mid B_j)P(B_j)$ ——证据 / 归一化常数 ,与具体的 $B_i$ 无关。
2.4 一个关键观察:分母是常量
注意分母 $P(A)$ 对所有 $B_i$ 都一样 ——它只是把分子归一化。于是后验与「似然 × 先验」成正比:
$$ \underbrace{P(B_i\mid A)}_{\text{后验}} \;\propto\; \underbrace{P(A\mid B_i)}_{\text{似然}}\;\times\;\underbrace{P(B_i)}_{\text{先验}}. \tag{2.4}$$
这条「正比关系」在工程上极其好用,它给了我们两种处理分母的方式:
做推断(比大小) :只想知道哪个 $B_i$ 更可能,分母可以完全不算——直接比较各分子即可。要完整后验(求数值) :把各分子算出来后做归一化 (除以它们之和)即可,因为所有后验加起来必为 1。
◆ 记号切换说明
课堂上常把 $B_i$ 换写成 $\theta$(模型参数)、把 $A$ 换写成 $X$(观测数据),于是贝叶斯定理写作
$$ P(\theta\mid X)=\frac{P(X\mid\theta)\,P(\theta)}{P(X)} ,\qquad P(X)=\sum_\theta P(X\mid\theta)P(\theta)\ \text{或}\ \int P(X\mid\theta)P(\theta)\,d\theta. \tag{2.5}$$
离散情形分母求和、连续情形分母积分,二者完全对称。本讲义两套记号都会出现,含义一致。
◆ 本章要点
条件概率 → 全概率 → 贝叶斯定理,三步打通「由果溯因」的通路。
后验 ∝ 似然 × 先验;分母是与参数无关的归一化常数。
「比大小」可略去分母,「求数值」做归一化——这是后续所有计算的省力总开关。
II
PART TWO
第二部分 贝叶斯推断与估计
Bayesian Inference and Estimation
先验、似然与后验,三种估计方法,Beta–Binomial 共轭。
第 3 章 先验、似然、后验 机床诊断与抛硬币 第 4 章 推断、学习与估计 同一公式的三种用途 第 5 章 参数估计:MLE、MAP 与贝叶斯估计 三种估计准则 第 6 章 共轭先验与 Beta 分布 从一枚硬币说起
第 3 章 先验、似然、后验:机床诊断与抛硬币把抽象公式落到两个能亲手推演的例子上
上一章给出了贝叶斯定理的形式。本章用两个例子把它落到可计算的具体数值 上:一个是工程性很强的机床故障诊断 (离散、强先验),一个是教科书经典的抛硬币 (连续、无信息先验)。机床这个例子尤其值得细品——我们将围绕它展开四点深入剖析 ,它们是理解贝叶斯方法的四块基石。
3.1 三个核心概念
◆ 先验 / 似然 / 后验
先验 Prior $P(\theta)$:在看到任何 具体观测数据之前,你对参数 $\theta$ 的初始信念。Initial information or belief about a parameter before considering any observed data. 似然 Likelihood $P(X\mid\theta)$:给定参数取值时,观测到这组特定数据的可能性。Probability of observing the specific data given a parameter value. 后验 Posterior $P(\theta\mid X)$:把数据考虑进来之后,对 $\theta$ 更新后的信念。Updated belief about a parameter after considering the observed data.
◆ 先验从哪里来?
三个来源——这正是「把经验注入模型」的入口:① 以往经验 (造币厂厂长知道硬币正反等概率);② 历史数据 (本组以前做过的实验规律);③ 主观判断 (领域专家的意见)。可靠性问题数据稀少而经验丰富,先验机制因此格外宝贵。
3.2 工程主线例子:机床故障诊断
设想你负责一台超精密磨床 (machine tool ,台湾称「工具机 / 工业母机」)。根据导师三十年的运维经验,它一旦停机故障,最可能是两种原因之一(为方便,令两者先验之和为 1):
表 3.1 机床故障的先验(来自历史运维经验)
故障假设 含义 先验 $P(B_i)$
$B_1$:电气短路 电路 / 电机短路烧毁 $0.20$ $B_2$:磨损退化 主轴 / 轴承磨耗(wear-out ) $0.80$
某天早上你进车间,闻到一股刺鼻的焦糊味 ,机床停机了。记这个观测为事件 $A$。凭经验,你给出两个似然:
$$ P(A\mid B_1)=0.9 \quad(\text{电气短路时闻到焦味的概率很高}),\qquad P(A\mid B_2)=0.1\quad(\text{纯磨损时闻到焦味的概率低}). $$
问题 :闻到焦味后,到底哪种故障更可能?即求后验 $P(B_1\mid A)$ 与 $P(B_2\mid A)$。代入贝叶斯定理 (2.3):
$$ P(B_1\mid A)=\frac{P(A\mid B_1)P(B_1)}{P(A\mid B_1)P(B_1)+P(A\mid B_2)P(B_2)}
=\frac{0.9\times 0.2}{0.9\times 0.2+0.1\times 0.8}=\frac{0.18}{0.26}\approx 0.69. \tag{3.1}$$
$$ P(B_2\mid A)=\frac{0.1\times 0.8}{0.26}=\frac{0.08}{0.26}\approx 0.31\;=\;1-P(B_1\mid A). \tag{3.2}$$
◆ 计算结果解读
一次观测,把判断彻底翻转 :电气短路的可能性从先验的 20% 升到约 69% ,磨损从 80% 降到约 31%。先验(历史经验)与观测(焦味这条证据)都被诚实地用上了——这就是后验更新的力量。这个看似简单的结果,可以从四个角度深入挖掘。
3.3 机床例的四点深入剖析
下面四点,是这门课希望你记入笔记 的核心认识。它们都从上面这台机床的诊断生长出来,却通向贝叶斯方法的全部要害。
点一 从一次更新到连续递推:模型会「持续学习」
上面只是一次 观测。如果第二天又出现新的现象呢?办法是:把这次的后验当作下一次的先验 ,再套一遍贝叶斯定理。于是「今天早上的后验」就成了「明天早上的先验」,更新可以一轮接一轮地进行下去:
$$ P(\theta)\;\xrightarrow[\;A_1\;]{\text{似然}}\;P(\theta\mid A_1)\;\xrightarrow[\;A_2\;]{\text{似然}}\;P(\theta\mid A_1,A_2)\;\xrightarrow{\quad}\;\cdots $$
◆ 要点一
有了「先验 → 似然 → 后验」这条完整通路,模型就具备了连续、递推式的更新能力 ——它能随每一次新观测在线学习、与时俱进 ,而不必像常规神经网络训练那样依赖成批的离线梯度更新(需说明:一般贝叶斯模型的精确递推仅在共轭等情形下是闭式的,复杂情形可能需要近似推断)。后验充当下一次先验,是贝叶斯方法「会持续学习」的根源。
点二 分母是常量:推断「比大小」,更新「做归一化」
观察 (3.1)、(3.2) 的分母:$P(A)=P(A\mid B_1)P(B_1)+P(A\mid B_2)P(B_2)=0.26$。它对每一个 假设都相同,是一个与具体 $B_i$ 无关的常量 。于是后验与分子成正比,处理分母有两种方式:
做推断(比大小) :只想知道哪种故障更可能时,分母可以完全不算 ——直接比较两个分子 $0.9\times0.2=0.18$ 与 $0.1\times0.8=0.08$,$0.18>0.08$,即判电气短路。当项数很多时,这能省下大量计算。要完整后验(求数值) :需要具体概率时,把各分子算出后做归一化 即可:$\dfrac{0.18}{0.18+0.08}\approx0.69$、$\dfrac{0.08}{0.18+0.08}\approx0.31$。分子之和 $0.18+0.08=0.26$ 一般并不等于 1;正是除以这个和(即归一化)之后 ,两个后验才恰好相加为 1。
◆ 要点二
贝叶斯定理的分母(全概率)是常量。推断只需比较分子的大小;要完整后验则对分子归一化。 两条路都绕开了直接计算分母,是后续所有计算的省力总开关,也正是第 2 章 (2.4) 正比关系在本例的落地。
点三 脱离先验比例谈观测,没有意义:基率的支配作用
更新后的结果呈现一种「反向分布」 :先验是电气 20%、磨损 80%,后验却翻成约 69% 对 31%。这提醒我们:先验比例(基率)与观测,二者缺一不可 。
把这一点推向极端,就得到一个反直觉 的重要结论。设想把「机床故障」换成「某种疾病的检测」:
⚠ 脱离基率谈「检测有多准」是没有意义的
若某病在人群中极其罕见 ,那么即便检测灵敏度很高、假阳性率很低,由于健康人基数巨大 ,「假阳性」一项仍可能主导 分母——结果是:检测呈阳性者中,真正患病的比例可能低得惊人。也就是说,单凭「这台检测仪 / 这个试剂多准」而不看该事件本身的发生比例(基率) ,是得不出可信结论的。低基率下检测并非毫无价值(一次阳性仍能把患病概率抬高若干倍),但单次阳性结果的确诊力 会很弱;只有当基率不低时,单次阳性才足以支撑可靠判断。
◆ 要点三
后验由先验比例 与似然 共同决定。脱离基率单谈观测/检测的准确度,会导出错误判断——这正是基率谬误 。第 11 章将用 HIV 检测把它定量做实(95% 灵敏、98% 特异、0.1% 患病率 $\Rightarrow$ 阳性真患病概率仅约 4.5% )。
点四 从离散到连续:后验是一条「分布」,看的是可能性与期望
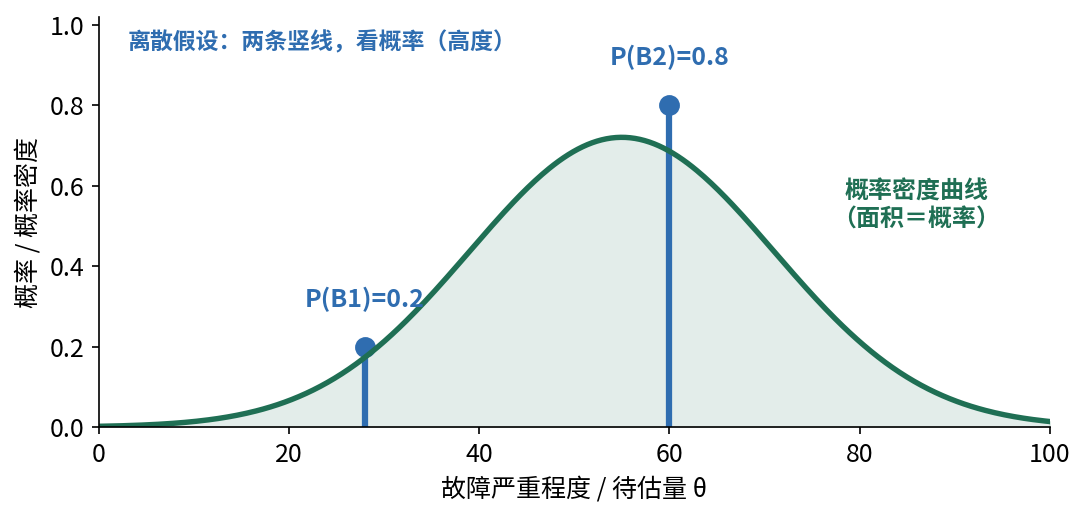
上例的故障只有两种离散假设,先验是两条竖线(0.2 与 0.8)。但若你关心的不是「哪种故障」,而是故障的严重程度 这类连续量,情况就不同了。请注意:这并不是把 0.2 / 0.8 这两根竖线「拉」成一条曲线,而是把待估量本身换成了一个连续参数 (如严重程度 $s$ 或寿命参数 $\theta$)——先验、似然、后验都改写在这个连续量上。此时先验是一条概率密度曲线 (其形状可借助威布尔等可靠性常用分布族来承载设计手册知识与历史数据),全概率公式中的求和也相应变为积分 ,更新后得到的后验是一条新的密度曲线。
图 3.2 离散 vs 连续。离散 情形(蓝色竖线):先验是两根竖线,看的是概率 ——竖线高度即 $P(B_1)=0.2$、$P(B_2)=0.8$。连续 情形(绿色曲线):待估量换成一个连续参数,先验是一条概率密度曲线 ,看的是密度 ——曲线下的面积才是概率。这正是从「看概率」到「看密度」的转变。
◆ 要点四
贝叶斯给出的从来不是「设备明天一定坏」这样的单点断言,而是一条带不确定性的分布 ——它看的是可能性与期望 。这与现代工程语言完全一致:快递说「95% 概率明天送达」、医生说「有百分之多少的可能」、可靠性工程问「明天设备失效的概率是多少」。也正因为给的是分布、且能随新信息实时更新 ,贝叶斯才成为预测与决策的有力工具。
3.4 经典例子:抛硬币与 Beta 分布
再看一个无信息先验 的例子,与机床的「强先验」恰成对照。一枚均匀性未知的硬币,正面概率 $\theta$ 未知。我们对它一无所知 ,于是假设 $\theta$ 在 $[0,1]$ 上均匀分布——即 $\mathrm{Beta}(1,1)$,称为无信息先验 (non-informative prior )。
图 3.1 课堂交互演示:硬币正面概率 $\theta$ 的置信度分布。起点是 Beta(1,1) 均匀分布——「正面概率在 0~1 之间任何值都等可能」。每观察一次正/反面,分布就更新一次。
接着抛 10 次,观测到 7 次正面 。给定 $\theta$,这一观测的似然由二项分布给出:
$$ L(x)=\binom{10}{7}\,\theta^{7}\,(1-\theta)^{3}. \tag{3.3}$$
其中组合系数 $\binom{10}{7}$ 与 $\theta$ 无关,在做归一化或求 $\arg\max$ 时可约去(即点二的思想,详见第 5 章)。用贝叶斯定理把先验 $\mathrm{Beta}(1,1)$ 与该似然相乘并归一化,得到后验。第 6 章会证明:这个后验恰好仍是一个 Beta 分布 :
$$ \text{先验 }\mathrm{Beta}(1,1)\;\xrightarrow[\;7\text{正}3\text{反}\;]{}\;\text{后验 }\mathrm{Beta}(1+7,\,1+3)=\mathrm{Beta}(8,4). \tag{3.4}$$
◆ 三种学派在这枚硬币上的不同回答
经典概率 :先验地认 $0.5$,抛多少次都不动。频率学派 :$7/10=0.7$,由频率定死。贝叶斯 :先给 $\mathrm{Beta}(1,1)$,据观测更新为 $\mathrm{Beta}(8,4)$;它不武断地说「$\theta$ 一定等于 0.7」,而是给出一条分布——$\theta=0.7$ 附近可能性最大,但别的值也有概率 (呼应点四)。
更进一步:若注入有信息 的先验(如 $\mathrm{Beta}(5,5)$,认为 $\theta$ 大概率在中间),更新后的后验会同时反映「你的经验」与「新数据」——这正是数据与经验融合建模的数学体现。
◆ 本章要点
先验=既有信念,似然=数据在参数下的可能性,后验=更新后的信念。
机床例:先验 0.2/0.8 经焦味观测更新为约 0.69/0.31,判断被一次观测翻转。
四点剖析 :① 后验变先验 → 连续递推更新;② 分母是常量 → 比大小 / 归一化;③ 脱离基率谈观测无意义 → 基率谬误;④ 离散到连续 → 后验是分布、看可能性与期望。抛硬币:$\mathrm{Beta}(1,1)\to\mathrm{Beta}(8,4)$,贝叶斯给出的是分布而非单点——伏笔留给第 6 章的共轭。
第 4 章 贝叶斯的三种用途:推断、学习、估计同一公式的三种使用方式
贝叶斯定理只有一个,但在工程中有三种典型用法:推断(Inference)、学习(Learning)、估计(Estimation) 。三者本质都是「先验 → 似然 → 后验」,区别在于你把什么当作已知、想求什么 。分清它们,读论文时就不会被术语绕晕。
4.1 推断 Inference —— 对未知状态的判定
◆ 定义
基于观测数据,更新对某个假设或参数的信念,用以判定一个未知状态 。一句话:已知 $Y$,问 $X$ 是什么? ——即如何从观测反推世界的状态。
$$ p(X\mid Y)\;\propto\;\underbrace{p(Y\mid X)}_{\text{似然}}\;\underbrace{p(X)}_{\text{先验}}. $$
这里有三类变量:未知量 (unknowns,待求)、观测量 (observables,可见)、辅助量 (auxiliary)。推断就是由观测量确定未知量 ,而似然与先验都是「模型」——它们承载知识。
前面两个例子都是推断:
机床:已知「闻到焦味」($Y$),判定「哪种故障」($X$)。
疾病诊断:已知「检测阳性」,判定「是否患病」(见第 11 章)。
推断的关键特征:模型本身是固定的 (检测能力、人群患病率已知),我们只是对某个具体个体下判断。
4.2 学习 Learning —— 模型能力的迭代与进化
◆ 定义
随着新数据不断到来,更新模型自身的参数 ,使其预测/分类能力越来越强。这正是机器学习中分类、回归任务的常见做法。
▶ 例子:垃圾邮件检测(朴素贝叶斯分类器)
大模型时代之前,垃圾邮件检测主要看关键词组合 :先给一个先验(垃圾邮件占比,如 5%~10%),再根据某些关键词出现与否更新「是垃圾邮件」的后验概率。学校邮箱拦得比商业邮箱严,是因为它持续在学习——今天的模型和昨天的不一样 :一旦某些新话术(如近期高频的某类请托、讲座推广)被标记为垃圾,模型对含这些词的邮件的判定概率就会上升。明天再来同类邮件,被判为垃圾的概率一定比今天更大。这就是「模型在学习」。
注意它与推断的根本差别:推断用 固定模型,学习则让模型本身迭代进化 。
4.3 估计 Estimation —— 具体数值的计算与寻优
◆ 定义
结合先验知识与观测数据,估计某个参数的具体数值 。例如:估计中山大学全体学生身高的均值与方差。
一个参数的估计量(estimator )是数据的某个函数,我们希望它接近真值。给定数据 $D$,参数 $\theta$ 的后验为
$$ p(\theta\mid D)=\frac{p(D\mid\theta)\,p(\theta)}{p(D)},\qquad p(D)=\int p(D\mid\theta)\,p(\theta)\,d\theta. \tag{4.1}$$
把分布求出来之后,「$\theta$ 到底等于多少」还可以有不同取法——取众数(MAP)、取均值等等。这一步留到下一章(MLE / MAP / 贝叶斯估计)展开。注意 (4.1) 与机床例子结构完全一致:那里分母是两项求和 ,这里换成积分 而已。
4.4 推断 vs 学习:一张对照表
这是课堂上专门强调的辨析,可靠性工程师尤其要分清——因为「故障诊断」属推断,而「自适应模型」属学习。
表 4.1 Bayesian Inference 与 Bayesian Learning 的对照
维度 贝叶斯推断 Inference 贝叶斯学习 Learning
定义 用贝叶斯定理,依观测更新对某假设/参数的信念 随新数据到来,动态更新模型参数 目的 计算「给定数据下某假设」的概率 优化模型参数,提升预测/分类精度 主要动作 先验 × 似然 → 算后验 持续更新参数、随新数据调整 应用 医学诊断、故障检测 、事件预测、假设检验 分类、回归、动态系统建模、在线学习、自适应滤波 例子 疾病诊断、系统可靠性评估 垃圾邮件分类、金融市场预测
◆ 应用注记
贝叶斯更新被广泛用于体育赛事与选举结果的实时预测:某支球队的胜率并非由静态的「纸面实力」决定,而是随转会、伤病、主客场、近期状态等新信息持续修正。实时更新 正体现了贝叶斯方法处理动态信息、随世界变化而调整的核心优势。
◆ 本章要点
推断 :用固定模型,判定个体的未知状态(故障诊断、疾病诊断)。学习 :让模型参数随数据进化(垃圾邮件、自适应系统)。估计 :求参数的具体数值,后验由 (4.1) 给出,离散求和 / 连续积分。三者同源,区别只在「已知什么、求什么」。
第 5 章 参数估计三法:MLE、MAP 与贝叶斯估计拿到后验之后,「$\theta$ 到底等于多少」的三种回答
第 4 章把后验分布求了出来。但工程上常常还要落到一个具体数值 :硬币正面概率是多少?故障率是多少?这就是参数估计。本章给出三种主流估计,并在抛硬币上把它们算通。
5.1 三种估计的定义
◆ 最大似然估计 MLE(Maximum Likelihood)
让「得到当前观测数据」的可能性最大——只看似然 ,不用先验:
$$ \hat\theta_{\mathrm{ML}}=\arg\max_{\theta}\,p(D\mid\theta). \tag{5.1}$$
◆ 最大后验估计 MAP(Maximum a Posteriori)
让后验 最大——相比 MLE,多了对先验的考虑:
$$ \hat\theta_{\mathrm{MAP}}=\arg\max_{\theta}\,p(\theta\mid D)=\arg\max_{\theta}\,p(D\mid\theta)\,p(\theta). \tag{5.2}$$
第二个等号成立,是因为 $p(\theta\mid D)=\dfrac{p(D\mid\theta)p(\theta)}{p(D)}$,而分母 $p(D)$ 中不含 $\theta$ (已被积分掉),对 $\arg\max$ 无影响。
◆ 贝叶斯估计(Bayesian Estimation)
设计一个损失函数 $L(\theta,\alpha)$($\theta$ 真值、$\alpha$ 估计值),最小化其后验期望:
$$ \hat\theta_{\mathrm{BAYES}}=\arg\min_{\alpha}\,\mathbb{E}\!\left[L(\theta,\alpha)\mid D\right]. \tag{5.3}$$
损失函数可取不同形式,对应不同的最优估计:平方损失 → 后验均值;绝对值损失 → 后验中位数;0-1 损失 → 后验众数(即 MAP) 。由此可见,MLE、MAP 与贝叶斯估计可在「损失函数」框架下统一理解。
◆ 三者关系(一句话记住)
MLE 只用似然 ;MAP = MLE + 先验 (在似然上乘先验后取峰值);贝叶斯估计用整条后验 并引入损失函数,是最完整、也最贵的一种。
5.2 例子:抛硬币的 MLE
抛硬币得到 $h$ 次正面、$t$ 次反面。设正面概率为 $\theta$,则似然 $L(\theta)=\theta^{h}(1-\theta)^{t}$(略去与 $\theta$ 无关的组合系数)。取对数后求导令其为零:
$$ \frac{d}{d\theta}\big[h\ln\theta+t\ln(1-\theta)\big]=\frac{h}{\theta}-\frac{t}{1-\theta}=0
\;\Longrightarrow\; \hat\theta_{\mathrm{ML}}=\frac{h}{h+t}. \tag{5.4}$$
结果朴素而合理:观测既然这么发生了,就找让它「最有道理发生」的 $\theta$。抛 10 次出现 7 正,则 $\hat\theta_{\mathrm{ML}}=0.7$。
5.3 例子:抛硬币的 MAP(均匀先验)
取无信息先验 $\theta\sim\mathrm{Beta}(1,1)$(均匀分布)。Beta 密度的一般形式为
$$ f(\theta;a,b)=\frac{1}{B(a,b)}\,\theta^{a-1}(1-\theta)^{b-1}, \tag{5.5}$$
其中 $B(a,b)$ 是只与 $a,b$ 有关的归一化常数。令 $a=b=1$,则 $\theta^{0}(1-\theta)^{0}=1$,密度退化为常数——正是 $[0,1]$ 上的均匀分布。
设 $n$ 次抛掷中有 $y$ 次正面。后验正比于先验 × 似然:
$$ p(\theta\mid y)\;\propto\;\underbrace{\theta^{y}(1-\theta)^{n-y}}_{\text{似然}}\;\cdot\;\underbrace{\theta^{a-1}(1-\theta)^{b-1}}_{\text{先验}}=\theta^{\,y+a-1}(1-\theta)^{\,n-y+b-1}. \tag{5.6}$$
这正是 $\mathrm{Beta}(y+a,\;n-y+b)$ 的核!于是后验为
$$ p(\theta\mid y)=\mathrm{Beta}(y+a,\;n-y+b). \tag{5.7}$$
利用 Beta 分布的众数公式 $\mathrm{Mode}=\dfrac{a-1}{a+b-2}$,对 $\mathrm{Beta}(y+1,\,n-y+1)$(即 $a=b=1$)有
$$ \hat\theta_{\mathrm{MAP}}=\frac{(y+1)-1}{(y+1)+(n-y+1)-2}=\frac{y}{n}. \tag{5.8}$$
◆ MAP 与 MLE 的一致性(均匀先验情形)
在均匀先验 下,$\hat\theta_{\mathrm{MAP}}=\dfrac{y}{n}=\hat\theta_{\mathrm{ML}}$——MAP 退化为 MLE。原因正是均匀先验「不注入任何信息」,于是后验峰值完全由似然决定。一旦换用有信息先验(如 $\mathrm{Beta}(5,5)$),MAP 就会被先验拉向中间,与 MLE 分离。
◆ 关键铺垫:先验与后验同族
式 (5.7) 暴露了一个极重要的现象:先验是 Beta、似然是二项 / 伯努利,后验仍是 Beta 。对一个 $\mathrm{Beta}(a,b)$ 先验,做 $n$ 次试验、$y$ 次成功后,只需把参数更新为 $a\leftarrow a+y,\ b\leftarrow b+(n-y)$ 即可。这就是共轭 ,第 6 章正式展开。
◆ 本章要点
MLE 只用似然;MAP 在似然上乘先验取峰值;贝叶斯估计用整条后验 + 损失函数。
抛硬币 MLE:$\hat\theta=h/(h+t)$;均匀先验下 MAP 退化为 MLE。
$\mathrm{Beta}$ 先验 + 二项似然 ⇒ 后验仍 $\mathrm{Beta}(y+a,n-y+b)$——共轭的伏笔。
第 6 章 共轭先验与 Beta 分布:从一枚硬币说起一个完整案例——看先验、似然、后验如何在形式上达成统一
本章是第二部分的收束,也是全书最值得细嚼的一章。我们不急于抛出「共轭」的定义,而是从一枚硬币出发,把一次完整的贝叶斯推理走到底 :先想清楚「拿到一枚来历不明的硬币该怎么猜」,再回头看经典与频率学派在这里的困境,然后用贝叶斯的方式做一次推导——推完你会惊讶地发现,先验与后验竟是同一种形式 。这绝非偶然,它背后是一个被称作共轭 的、极为高明的工程化技巧。
6.1 拿到一枚硬币:你会怎么猜?
桌上一枚来历不明的硬币,正面朝上的概率记为 $\theta$,未知。在抛它之前,你对 $\theta$ 已经可以有一个信念 。至少有三种态度:
不做任何猜测(无信息) :你对 $\theta$ 一无所知,认为 $0$ 到 $1$ 之间任何值都等可能。这对应均匀分布,即 $\mathrm{Beta}(1,1)$。基于常识的弱猜测 :常识告诉你硬币多半是公平的,$\theta$ 大概在 $0.5$ 附近。这对应一条对称、在中间隆起的分布,如 $\mathrm{Beta}(5,5)$。带强烈倾向的先验 :若你有理由相信它偏向某一面,可以给出偏斜的信念,如 $\mathrm{Beta}(1,2)$(偏向反面、$\theta$ 偏小)或 $\mathrm{Beta}(5,3)$(偏向正面、$\theta$ 偏大)。
这三种态度,都可以用同一族 定义在 $[0,1]$ 上的分布来表达——Beta 分布 。它正是描述「关于一个概率的信念」的天然语言:
◆ Beta 密度
$$ f(\theta;a,b)=\frac{1}{B(a,b)}\,\theta^{a-1}(1-\theta)^{b-1},\qquad 0\le\theta\le1,\ \ a,b>0. \tag{6.1}$$
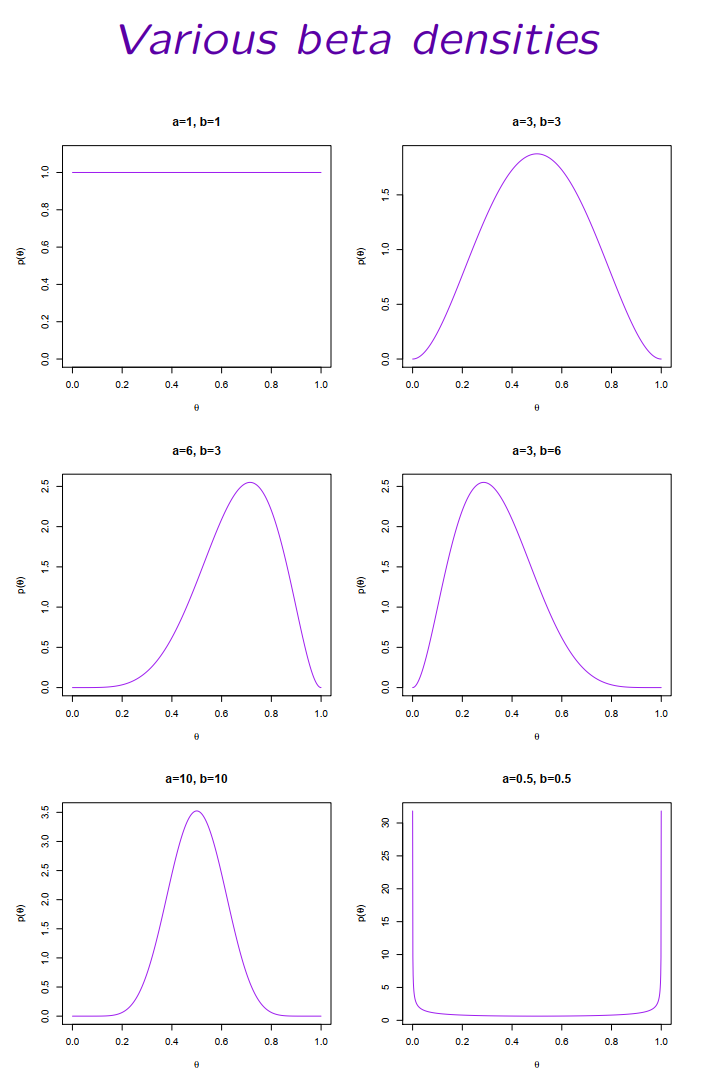
其中 $B(a,b)=\dfrac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)}$ 是与 $\theta$ 无关的归一化常数。两个超参数 $(a,b)$ 决定形状:$a>b$ 偏右、$a
图 6.1 不同超参数下的 Beta 密度。Beta(1,1) 是均匀分布(无信息);Beta(3,3)/Beta(10,10) 对称集中于 0.5、后者更尖锐;Beta(6,3) 偏右、Beta(3,6) 偏左。改变 $(a,b)$ 就能表达上面三种乃至更多先验态度。
6.2 经典与频率学派,在这枚硬币上的困境
先别急着算。同样一枚硬币,前两种概率观会怎么处理,又会遇到什么问题?
经典概率 :武断地认定 $\theta=0.5$。无论你抛多少次、看到什么,它都不更新 ——一旦硬币其实有偏,这个回答就是错的,而它没有自我纠正的机制。频率学派 :抛 $n$ 次、$y$ 次正面,给出 $\hat\theta=y/n$。它有两处软肋:其一,无法注入任何先验经验 (哪怕你早知道这类硬币几乎都公平,也用不上);其二,少量样本极不可靠 ——只抛 2 次得 1 正 1 反,难道就断定 $\theta=0.5$?没人敢下这个结论。
◆ 贝叶斯的立场
贝叶斯既不武断地钉死,也不把结论交给孤零零的频率。它先给一个先验信念(一条 Beta 曲线),再依据观测去更新它 ——经验与数据由此被同时、诚实地用上。下面就把这次更新从头算一遍 。
6.3 贝叶斯的做法:先验 × 似然
设先验为 $\theta\sim\mathrm{Beta}(a,b)$,即式 (6.1)。现在抛 $n$ 次,观测到 $y$ 次正面。给定 $\theta$,这组观测的似然 由二项分布给出:
$$ P(\text{data}\mid\theta)=\binom{n}{y}\,\theta^{y}(1-\theta)^{n-y}. \tag{6.2}$$
由贝叶斯定理,后验正比于「似然 × 先验」,再除以与 $\theta$ 无关的证据 $P(\text{data})$ 做归一化。我们把它完整地 写出来。
6.4 从头推导:先验与后验,形式上的统一
把似然 (6.2) 与先验 (6.1) 相乘、再除以归一化积分:
$$ P(\theta\mid\text{data})=
\frac{\dbinom{n}{y}\theta^{y}(1-\theta)^{n-y}\cdot\dfrac{1}{B(a,b)}\theta^{a-1}(1-\theta)^{b-1}}
{\displaystyle\int_0^1 \dbinom{n}{y}\theta^{y}(1-\theta)^{n-y}\cdot\dfrac{1}{B(a,b)}\theta^{a-1}(1-\theta)^{b-1}\,d\theta}. \tag{6.3}$$
第一步 :分子分母里都含有与 $\theta$ 无关的常数 $\dbinom{n}{y}\big/B(a,b)$,上下抵消 。剩下的只是 $\theta$ 的幂次相乘——把指数合并:$\theta^{y}\cdot\theta^{a-1}=\theta^{\,y+a-1}$,$(1-\theta)^{n-y}\cdot(1-\theta)^{b-1}=(1-\theta)^{\,n-y+b-1}$:
$$ P(\theta\mid\text{data})=\frac{\theta^{\,y+a-1}(1-\theta)^{\,n-y+b-1}}{\displaystyle\int_0^1\theta^{\,y+a-1}(1-\theta)^{\,n-y+b-1}\,d\theta}. $$
第二步 :分母那个积分,正是 Beta 函数的定义 $\displaystyle\int_0^1\theta^{p-1}(1-\theta)^{q-1}d\theta=B(p,q)$,此处 $p=y+a,\ q=n-y+b$。于是
$$ P(\theta\mid\text{data})=\frac{1}{B(y+a,\,n-y+b)}\,\theta^{\,y+a-1}(1-\theta)^{\,n-y+b-1}. \tag{6.4}$$
◆ 惊人的发现
把 (6.4) 与先验 (6.1) 摆在一起看——它们的形式一模一样 ,都是 $\dfrac{1}{B(\cdot,\cdot)}\theta^{\,\square-1}(1-\theta)^{\,\square-1}$!也就是说,后验仍是一个 Beta 分布,只不过参数从 $(a,b)$ 变成了
$$ \boxed{\;\mathrm{Beta}(a,b)\ \xrightarrow[\;y\text{ 正},\ n-y\text{ 反}\;]{}\ \mathrm{Beta}(a+y,\ b+n-y)\;} \tag{6.5}$$
更新一个先验,竟然只是把正面数加到 $a$、反面数加到 $b$ 。这正是当年讲到此处时令人「震惊」的地方。
6.5 这不是偶然:共轭,一种工程化的技巧
「Beta 进、Beta 出」并不是这枚硬币的巧合,而是先验与似然般配 时的普遍现象,背后有深刻内涵。我们给它一个名字:
◆ 共轭(Conjugacy)
给定一族似然函数,若后验与先验属于同一个分布族 ,则称先验与后验关于该似然共轭 ,该先验称为这族似然的共轭先验 。Beta 是 伯努利 / 二项 似然的共轭先验 。
◆ 为什么说它是「工程化技巧」
与其说共轭是高深的数学,不如说它是一种让贝叶斯计算真正可落地的设计智慧 。它带来两个决定性的好处:
闭式后验,下面不用算 :(6.3) 那个看着吓人的积分(归一化常数)根本不必硬算——只要认出分子的形状是 Beta 的核,后验参数立刻可写。可无限递推,形成闭环 :后验仍是 Beta,可直接当作下一轮的先验 继续更新,数学上永远「解得下去」。若先验与似然不共轭,后验往往复杂到再也无法解析迭代。
所以,在设计先验与似然时,优先选用共轭组合 ,是一项极其实用的工程考量——这也正是它配得上「高明技巧」之名的原因。
6.6 参数即累积观测:读懂 Beta(1,1) → Beta(10,10)
更新规则 (6.5) 还藏着一个漂亮的解读。从「零信息」的 $\mathrm{Beta}(1,1)$ 出发,做 $18$ 次观测、$9$ 次正、$9$ 次反,则
$$ \mathrm{Beta}(1,1)\ \xrightarrow[\;9\text{ 正},\ 9\text{ 反}\;]{}\ \mathrm{Beta}(1+9,\ 1+9)=\mathrm{Beta}(10,10). $$
◆ 先验的「伪计数」解读
反过来看,一个 $\mathrm{Beta}(a,b)$ 先验,等价于「在均匀起点 $\mathrm{Beta}(1,1)$ 上、已经观测到 $(a-1)$ 次正、$(b-1)$ 次反」 ——$(a-1,b-1)$ 就是先验携带的伪计数 (pseudo-count )。于是:
$\mathrm{Beta}(10,10)$ 相当于「我心里已经见过约 9 次正、9 次反」,所以它笃定地集中在 $0.5$ 附近(图 6.1)。
$a+b$ 越大 ⇒ 伪计数越多 ⇒ 先验越「重」、越自信,新数据要更多才能撼动它。
因此「已知先验是 $\mathrm{Beta}(6,6)$ 」与「从 $\mathrm{Beta}(1,1)$ 出发、抛 10 次得 5 正 5 反 」在数学上完全等价 。
一句话:先验与数据,是在同一把尺子上累加的。 这把「经验」与「观测」统一成了可加的计数,正是贝叶斯优雅之所在。
6.7 共轭不止一对(承上启下)
伯努利 / 二项 与 Beta 只是最先遇到的一组。共轭组合还有很多,且各有其适用的数据类型:
表 6.1 几组常用共轭对(详表与可靠性应用见第 14 章)
似然 Likelihood 共轭先验(后验同族) 典型场景
伯努利 / 二项 Bernoulli / Binomial Beta 成功率、缺陷率(抛硬币) 泊松 Poisson Gamma 单位时间计数(故障率) 正态 Normal(估均值) Normal 含噪测量(高斯最常见)
实践中正态似然尤为常见(我们常把似然设为高斯),其共轭先验可取 Normal / Gamma / Inverse Gamma,选择灵活。第 14 章将系统列出共轭族,并把它们用到可靠性工程 ——如用 Gamma–Poisson 给故障率建模、用 Gamma–Exponential 做剩余寿命估计。
◆ 评注
共轭性把贝叶斯更新化繁为简:一来「下面那个积分不用算」,二来更新过程是封闭的——$\mathrm{Beta}(1,1)$ 经 5 正 5 反成为 $\mathrm{Beta}(6,6)$,而直接以 $\mathrm{Beta}(6,6)$ 为先验,二者本质毫无区别。先验、似然、后验由此构成一个可以一直转下去的闭环;这正是设计贝叶斯模型时,优先追求共轭的根本原因。
◆ 本章要点
面对未知硬币的三种先验态度(无信息 / 弱 / 强),都可用 Beta$(a,b)$ 表达;经典与频率学派各有困境,贝叶斯靠「先验 × 似然」更新。
从头推导得 $\mathrm{Beta}(a,b)\xrightarrow{y\text{正},\,n-y\text{反}}\mathrm{Beta}(a+y,\,b+n-y)$——后验与先验形式一致 ,常数上下抵消、分母积分恰为 Beta 函数。
这一现象即共轭 :闭式后验 + 可无限递推,是让贝叶斯计算落地的工程化技巧。
参数即累积观测:$\mathrm{Beta}(10,10)$=均匀起点上 9 正 9 反;$(a-1,b-1)$ 是先验的伪计数,经验与数据在同一把尺上相加。
III
PART THREE
第三部分 混合模型与 EM 算法
Mixture Models and the EM Algorithm
模型复杂度,高斯混合模型,期望最大化算法,以及诊断检测中的基率谬误。
第 7 章 模型复杂度与分段建模 代价与收益的权衡 第 8 章 混合模型与高斯混合模型 加权叠加 第 9 章 EM 算法 期望最大化 第 10 章 模型选择:AIC 与 BIC 拟合与复杂度 第 11 章 诊断检测与基率谬误 HIV 检测案例
第 7 章 模型复杂度与分段建模一个模型不够用时,代价与收益的博弈
进入第三部分,我们从一个朴素的工程困惑开始:当单一模型刻画不了数据时怎么办? 最直接的想法是「分段」——把数据切成几段、各用一个简单模型。但分段并非没有代价。本章把这笔账算清楚,并由此自然引出下一章的混合模型。
7.1 分段的代价:参数膨胀
用一条直线 $y=ax+b$ 拟合,只要 2 个参数。若把定义域切成 3 段,参数会多出来:
每段之间的分段点位置 ——3 段有 2 个内部分段点;
每段各自的 $a,b$——3 段就是 $3\times2=6$ 个。
于是参数从 2 个增加到 8 个(每段 $y=ax+b$ 共 $3\times2=6$ 个,加 2 个分段点位置)。分得越细,参数越多;参数越多、自由度越高,就越容易拟合噪声——这正是下一节过拟合的根源。
7.2 分段的隐患:信息割裂与过拟合
把数据切分后,每一段都看不到其它段的信息 。若某段本身含噪声,建模就容易被噪声带偏。一个极端的反例最能说明问题:
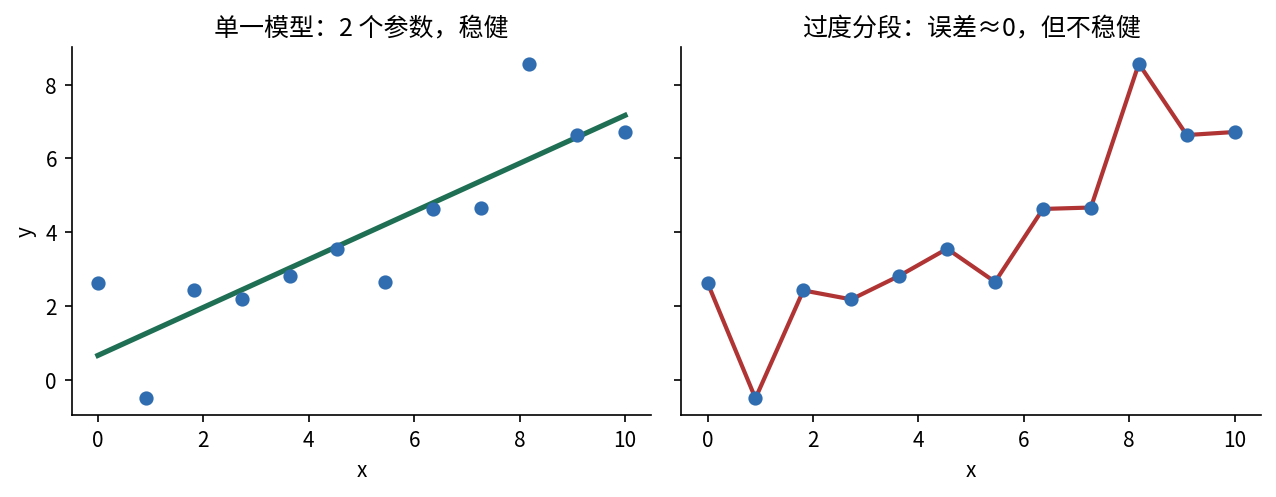
⚠ 100 个点、99 条线段的陷阱
给 100 个数据点,每相邻两点连一段,做 99 条线段——拟合误差精确为零 。但这个模型毫无意义:它极不稳健,换一组测点就完全跑偏。误差最小 ≠ 模型最好。
图 7.1 复杂度的两难。左 :单一直线只有 2 个参数,对噪声不敏感、稳健;右 :把每相邻两点连成线段,拟合误差降到近乎为零,但模型紧贴噪声、极不稳健——换一组测点就面目全非。这就是「误差最小 ≠ 模型最好」。
所以分段建模本质是一门折中的艺术 :分多少段、在哪里分,听起来非常经验(empirical ),需要大量假定、推测与验证。它相对单一模型唯一确定的好处是「误差变小」,其余全是要权衡的负担。
7.3 什么样的分段才「有道理」
分段要分得有依据——背后得有合理的先验 。
▶ 例子:用模型刻画中山大学学生的体重分布
若直接拿一个模型套全体学生,不如按性别分成男、女两组各建一个模型 ——后者一定更准。因为「性别」是一个天然、有道理 的划分依据,它对应真实存在的两个子群。反之,硬把人群分成「10 个莫名其妙的类」就没有先验支撑,是无意义的过度分段。
这个例子也埋下伏笔:男生、女生各是一个高斯,整体就是两个高斯的叠加 ——这正是下一章混合模型的雏形。
7.4 分段的连接问题 → 走向混合模型
简单分段还有个毛病:分段连接处往往不连续、不光滑、不可导 ,对建模不利。怎么办?把硬切换成软叠加 ——不再用「非此即彼」的分段,而是把若干个分布按权重相加 ,让它们平滑地融合。
◆ 从分段到混合:思路的转变
分段:把数据切开 ,每段一个模型,硬拼接 → 不连续。多个分布的加权叠加 ,每个点以一定「归属概率」属于各成分 → 平滑、可导、参数更省。高斯混合模型(GMM) 与 EM 算法 登场的地方。
◆ 本章要点
分段会带来参数膨胀与信息割裂;「99 段零误差」是过拟合的典型反例。
误差最小 ≠ 模型最好;分段须有合理先验(如按性别分组)。
把「硬分段」改造为「软混合」,即引出 GMM 与 EM。
第 8 章 混合模型与高斯混合模型(GMM)把多个简单分布「加权叠加」,刻画复杂数据
上一章把「硬分段」转向「软混合」。本章给出混合模型的精确形式,并聚焦工程中最常用的高斯混合模型(GMM) 。它回答的问题是:当数据明显由几个子群构成时,如何用一个统一的概率模型去描述?
8.1 混合模型的定义
◆ 混合模型(Mixture Model)
用若干个分布的加权叠加 来做密度估计:
$$ p(x)=\sum_{i=1}^{K} p_i\,h(x;\theta_i),\qquad p_i>0,\ \ \sum_{i=1}^{K}p_i=1. \tag{8.1}$$
$K$:混合成分的个数;
$h(x;\theta_i)$:第 $i$ 个成分的概率密度(component pdf ),参数为 $\theta_i$;
$p_i$:混合权重 (mixture weight ),即「某观测来自第 $i$ 个成分」的概率,也就是该成分的类先验 (单次抽取服从类别分布 Categorical ,其 $n$ 次独立重复的推广即多项分布)。
8.2 高斯混合模型(GMM)
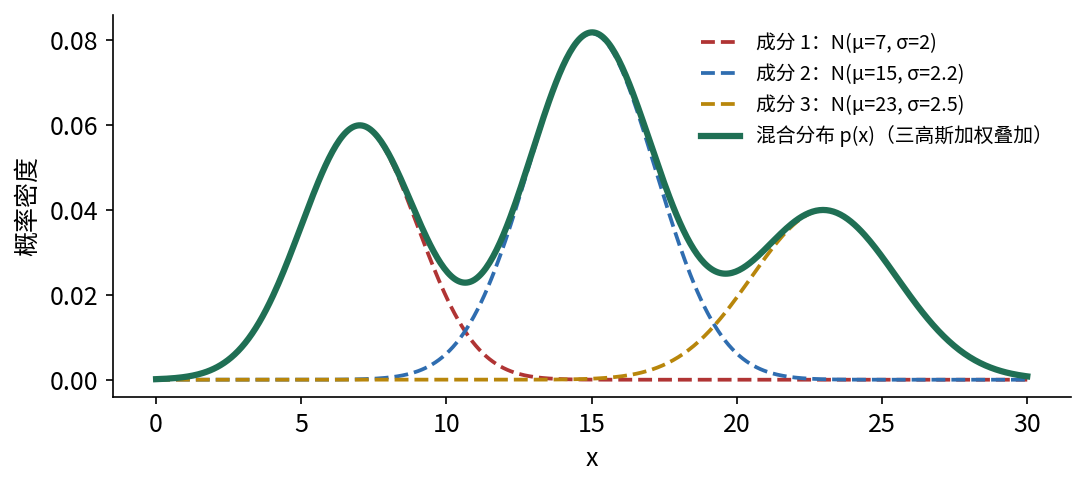
当每个成分都取高斯分布、但均值与方差各不相同 时,混合模型就成了 GMM 。例如把三个不同的高斯按权重叠加:
$$ p(x)=\sum_{i=1}^{3} p_i\,\mathcal{N}(x;\mu_i,\sigma_i^2). $$
一维(Univariate) :每个成分是一条钟形曲线,叠加后可呈现多峰。多维(Multivariate) :每个成分是一个多元高斯(带均值向量与协方差矩阵),叠加后描述高维数据的多个聚集团。
图 8.1 高斯混合模型:三个均值、方差各异的高斯成分(虚线)按权重 $p_i$ 叠加,得到一条多峰的混合分布(绿色实线)$p(x)=\sum_i p_i\,\mathcal{N}(x;\mu_i,\sigma_i^2)$。单一高斯只能描述一个峰,混合模型才能刻画「由多个子群构成」的复杂数据。
▶ 主线例子:按体重区分男生 / 女生
中山大学学生的体重,可看作两个高斯的混合:女生一个(均值小)、男生一个(均值大)。若已知 两个高斯的参数(如女生 $\mu\approx45,\ \sigma\approx5$;男生 $\mu\approx90,\ \sigma\approx10$,仅为讲解取值),对一名体重 40 kg 的个体,凭直觉即可判断其更可能是女生——这其实就是在比较两个成分的似然。难点在于:真实情况下我们既不知道参数,也不知道每个人的性别标签 。怎么办?这正是 EM 算法(第 9 章)要解决的。
8.3 核心难题:参数怎么估?
对单个高斯,估计 $\mu,\sigma$ 很容易(直接套样本均值、样本方差)。但 GMM 要同时估两类未知量:
每个成分的分布参数 $\theta_i=(\mu_i,\sigma_i)$;
每个成分的混合权重 $p_i$。
更麻烦的是,我们手上只有一堆没有标签 的数据点(不知道每个点来自哪个成分)。单一分布取对数后 $\ln\prod=\sum\ln$,可逐项求导得到闭式解;而混合模型的对数似然形如 $\displaystyle\sum_{n}\ln\Big(\sum_{i} p_i\,\mathcal{N}(x_n;\theta_i)\Big)$,对数套在内层求和之外 ,求导时各成分参数相互耦合、无法分离,因而没有解析解 ——这正是必须改用 EM 迭代的根本原因。
◆ 求解思路:引入隐变量并交替迭代
如果知道 每个点的归属(标签),参数估计就退化成各组单独的高斯估计——很简单。如果知道 参数,每个点的归属概率也能算出来。二者相互依赖、构成循环——既然如此,便先给定一组初值,再交替迭代 :这就是期望最大化(EM)算法 。
◆ 本章要点
混合模型 $p(x)=\sum_i p_i h(x;\theta_i)$,权重 $p_i$ 即类先验、满足归一。
GMM=成分均为高斯(均值方差各异)的混合,可单维或多维。
GMM 的参数(成分参数 + 权重)无法直接解析求解 → 引出 EM 算法。
第 9 章 EM 算法(期望最大化)在「不知道标签」的情况下,把混合分布的参数估出来
期望最大化算法 (Expectation–Maximization, EM )是一种迭代方法,用于在含隐变量 (如「每个点属于哪个成分」)时,求参数的最大似然 / 最大后验估计。本章用两个高斯的混合把 EM 走通——这是理解后续诊断、聚类乃至许多现代统计学习方法的基石。
9.1 EM 在做什么:一句话直觉
◆ EM 的基本思想
我们有一堆无标签 数据,假设它来自 $K$ 个高斯的混合,想估出各成分的 $(\mu_i,\sigma_i)$ 和权重 $p_i$。EM 的办法是:
先初始化 一组参数(即给定先验 / 初值);E 步 :在当前参数下,算每个点「属于各成分」的概率(即后验归属);M 步 :假设这些归属是对的,反过来重新估计 参数使期望对数似然最大;回到第 2 步,交替迭代 直到参数收敛。
9.2 E 步:计算归属(Expectation)
以两个成分为例:蓝 $B$(参数 $\mu_b,\sigma_b$)与红 $R$(参数 $\mu_r,\sigma_r$)。给定当前参数,点 $x_i$ 在各成分下的似然(高斯密度)为
$$ P(x_i\mid B)=\frac{1}{\sqrt{2\pi}\,\sigma_b}\,
e^{-\frac{(x_i-\mu_b)^2}{2\sigma_b^2}},\qquad
P(x_i\mid R)=\frac{1}{\sqrt{2\pi}\,\sigma_r}\,
e^{-\frac{(x_i-\mu_r)^2}{2\sigma_r^2}}. \tag{9.1}$$
再用贝叶斯定理,把似然转成后验归属 (membership / posterior )——点 $x_i$ 属于 $B$ 的概率:
$$ P_i^{B}=P(B\mid x_i)=\frac{P(x_i\mid B)\,P(B)}{P(x_i\mid B)\,P(B)+P(x_i\mid R)\,P(R)},\qquad
P_i^{R}=P(R\mid x_i)=1-P_i^{B}. \tag{9.2}$$
这正是一个标准的后验计算:先验 $P(B),P(R)$(初始可设相等 $0.5$)× 似然 (9.1),归一化即得归属。「期望」部分到此完成。
9.3 M 步:更新参数(Maximization)
M 步本质是一个加权的点估计 :用每个点的归属作权重,重新算各成分的均值与方差。属于 $B$ 的「软计数」越大,该点对 $B$ 参数的贡献越大。
◆ 参数更新公式
$$ \mu_b=\frac{\sum_{i} P_i^{B}\,x_i}{\sum_{i} P_i^{B}},\qquad
\sigma_b^2=\frac{\sum_{i} P_i^{B}\,(x_i-\mu_b)^2}{\sum_{i} P_i^{B}}. \tag{9.3}$$
(红成分 $\mu_r,\sigma_r^2$ 同理,用 $P_i^{R}$ 加权。)权重也一并更新——它就是各成分归属在全体样本上的平均:
$$ P(B)=\frac{1}{n}\sum_{i=1}^{n} P_i^{B},\qquad P(R)=\frac{1}{n}\sum_{i=1}^{n} P_i^{R}=1-P(B). \tag{9.4}$$
更新完 $\mu,\sigma,P$ 后,带着新参数回到 E 步重算归属,如此往复,直到参数不再变化(曲线趋于稳定)即收敛。
◆ 为什么 EM 一定收敛
可以证明:每次 E→M 迭代都使观测数据的对数似然单调不减 ;又因似然有上界,故 EM 必收敛 。但它只保证收敛到局部极大 ,对初值敏感——实践中常用多组不同初值分别重启,取最终似然最大者,以降低陷入较差局部解的风险。
▶ 例子:按体重聚成男 / 女两类
给一组无标签 的体重数据(实则由两个高斯采样而来,但「颜色 / 性别」对建模者是隐藏的)。EM 这样跑:
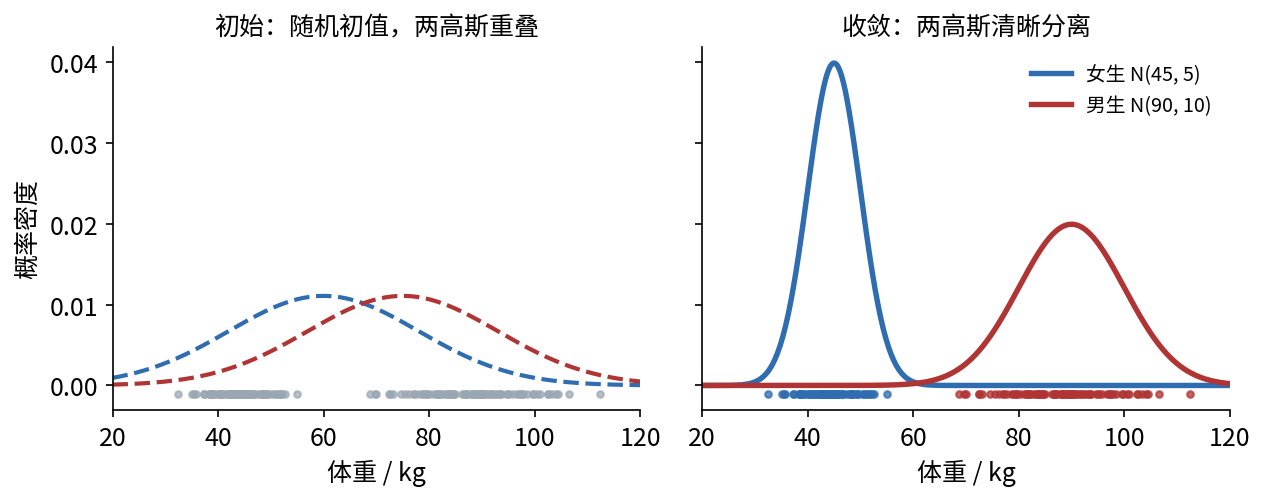
初始化 :假设两成分权重各 $0.5$,给 $(\mu_b,\sigma_b)$、$(\mu_r,\sigma_r)$ 一个初值(信息全无时可取相同初值;若已知「中国男女体重分布」可直接拿来当起点——好比从大模型做参数微调)。E 步 :对每个人算 $P_i^{B},P_i^{R}$(他/她更像男生还是女生)。M 步 :按归属加权,重算两组的 $\mu,\sigma$ 和权重。迭代 :通常数十轮内即收敛(具体轮数取决于数据可分性、初值与收敛阈值),两个高斯清晰地分离出来。
图 9.1 EM 在「按体重分男女」上的运行(取女生 $\mathcal{N}(45,5^2)$、男生 $\mathcal{N}(90,10^2)$ 采样)。左 :初始随机初值,两个高斯重叠、分不清;建模者看到的只是底部那排无标签的灰点。右 :约数十轮迭代后收敛,两个高斯清晰分离,数据点按归属被着色(蓝=女生、红=男生)。EM 在「不知道标签」的情况下,恢复出了隐藏的聚类结构。
◆ 一个有趣的细节:标签可互换
由于建模者并不知道真实「颜色」,最后画出的两类用哪种颜色标注是任意的 ——EM 可能把真实的「蓝」估成「红」。这不影响结果:两组本就对称,只是 $B/R$ 的命名对调而已。这提醒我们:EM 恢复的是聚类结构 ,而非预先指定的标签身份。
◆ 与初始化的关系:从零训练 vs 微调
「完全无信息 → 取相同初值从头估」就像从零训练一个模型 ;「拿已知的群体分布当初值」就像基于大模型做参数微调 。二者只是起点不同,迭代机制完全一致。
◆ 评注:为什么 EM 重要
许多实际分布难以用单一模型刻画,往往需要若干模型的混合。掌握「非参数化采样 + 混合模型 + EM 算法」这组方法后,即便分布形式未知,只要观测充分,原则上都可将其逼近、复刻出来。在测量等工程领域,噪声是首要难题,而这类基于数据的迭代估计正是应对噪声、从含噪观测中还原真实分布的有力工具。
◆ 本章要点
EM = E 步(按当前参数算后验归属)+ M 步(按归属加权重估参数),交替到收敛。
E 步是贝叶斯后验 (9.2),M 步是加权点估计 (9.3)–(9.4)。
它解决了「无标签下估计混合分布参数」的难题,是聚类与许多统计学习方法的内核。
第 10 章 模型选择:AIC 与 BIC当混合成分数 K 未知时,如何在「拟合」与「复杂度」之间取舍
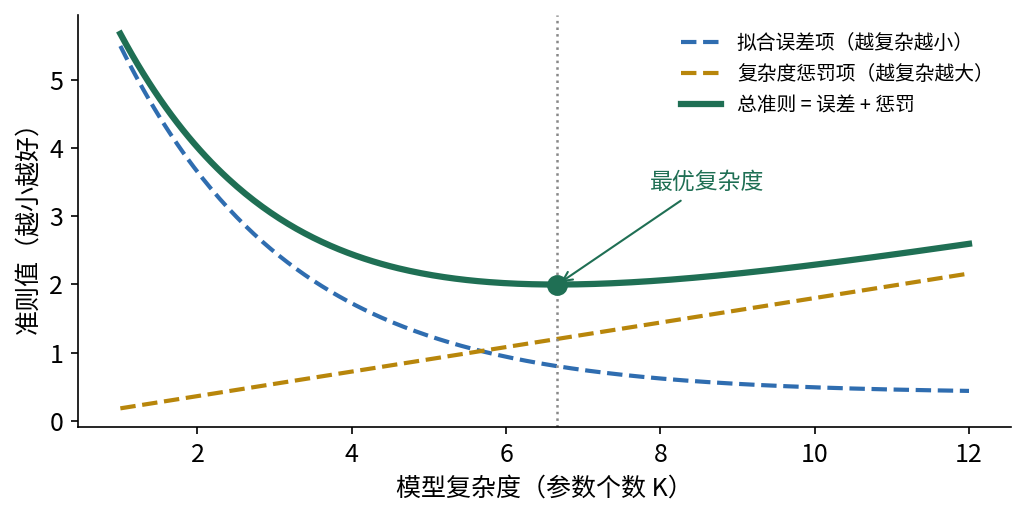
GMM 要事先指定成分数 $K$。但现实里 $K$ 常常未知——这又回到第 7 章那个老问题:到底分几段 / 几类才合适? 本质是模型精度 与模型复杂度 之间的权衡(trade-off )。AIC 与 BIC 就是把这个权衡量化的准则。
10.1 为什么需要复杂度惩罚
重温那个反例:用 99 条线段拟合 100 个点,误差为零却毫无意义。可见单看「拟合误差」会把我们引向越复杂越好 的歧路。所以好的准则必须由两部分相加:
$$ \text{准则}=\underbrace{\text{拟合优度项}}_{\text{越拟合越小}}+\underbrace{\text{复杂度惩罚项}}_{\text{越复杂越大}}. $$
最小化这个和,就能在「拟合好」与「别太复杂」之间找到平衡点。
图 10.1 拟合与复杂度的权衡。拟合误差项 (蓝虚线)随复杂度单调下降,复杂度惩罚项 (黄虚线)随复杂度单调上升;二者之和——总准则 (绿实线)——呈 U 形,其最低点即最优复杂度 。AIC 与 BIC 不过是给这两项以不同的具体取法(BIC 的惩罚更重,最优点更偏左、更简单)。
10.2 两个准则
◆ 赤池信息准则 AIC(Akaike Information Criterion)
$$ \mathrm{AIC}=2K-2\ln(L). \tag{10.1}$$
◆ 贝叶斯信息准则 BIC(Bayesian Information Criterion)
$$ \mathrm{BIC}=K\ln(n)-2\ln(L). \tag{10.2}$$
其中:$L$ 为模型的最大似然(拟合越好 $L$ 越大,$-2\ln L$ 越小);$K$ 为参数个数;$n$ 为样本量。两式都遵循「拟合优度 + 复杂度惩罚」的结构,取值越小的模型越优 。
表 10.1 AIC 与 BIC 的对比
拟合优度项 复杂度惩罚项 对参数的惩罚
AIC $-2\ln(L)$ $2K$ 较轻 BIC $-2\ln(L)$ $K\ln(n)$ 较重 (随样本量 $n$ 增长)
BIC 的惩罚项含 $\ln(n)$。当样本量 $n\ge 8$ 时(此时 $\ln n>2$,因两者相等点为 $\ln n=2\Rightarrow n=e^{2}\approx 7.39$),BIC 对每个参数的惩罚 $\ln n$ 超过 AIC 的 $2$,因而更偏好简单模型 。
10.3 与「损失函数」的统一视角
如果你做过机器学习或贝叶斯优化,会发现这与损失函数 是一回事:损失 = 拟合误差项 + 复杂度(正则 / 惩罚)项。用一个直观的写法:
$$ \text{Loss}(\text{模型})=\underbrace{\sum_{i=1}^{n}\text{err}_i^2}_{\text{拟合误差(如 MSE)}}+\;k\cdot f(M), \tag{10.3}$$
其中 $M$ 是模型复杂度(如参数个数),$f(\cdot)$ 是惩罚函数,$k$ 是可调系数。
◆ 系数 k 的作用
$k$ 取大 → 重罚复杂度,偏好简单模型 ;
$k$ 取小 → 轻罚复杂度,偏好高精度 。
它就是那个「惩罚项 (penalty )」——与拟合得多好无关,只约束模型别过分复杂。AIC/BIC 不过是给了 $k$ 与 $f$ 两种有理论依据的具体取法。
◆ 本章要点
$\mathrm{AIC}=2K-2\ln L$;$\mathrm{BIC}=K\ln n-2\ln L$;越小越优。
两者都是「拟合优度 + 复杂度惩罚」;BIC 惩罚更重,偏好简单模型。
这与损失函数 = 误差项 + 正则项 是同一思想,$k$ 控制你对复杂度的容忍度。
第 11 章 诊断检测与基率谬误:HIV 检测案例为什么「99% 准确的检测」可能是个陷阱——以及它对可靠性检测的警示
本章是贝叶斯定理在诊断检测 上的经典应用,也是一个极具冲击力的反直觉 结论。它和第 3 章的机床例子结构完全相同,但结论颇违直觉。对可靠性工程师而言,它直接关系到「一个检测工具是否可信」这一根本问题。
11.1 问题设定
已知一种新的 HIV 检测:
灵敏度(sensitivity)95% :真患病者被检出阳性的概率 $P(X=1\mid\theta=1)=0.95$;特异度(specificity)98% :真健康者被检出阴性的概率 $P(X=0\mid\theta=0)=0.98$,故假阳性 $P(X=1\mid\theta=0)=0.02$;人群患病率(prevalence)0.1% :$P(\theta=1)=0.001$。
问题 :某人检测呈阳性,他实际 患 HIV 的概率是多少?
◆ 定义事件(θ 与 X)
这正是前面反复强调的「$\theta$ 是参数、$X$ 是观测」:
未知参数(疾病状态)$\theta$:$\theta=1$ 患 HIV,$\theta=0$ 未患。先验 $P(\theta=1)=0.001,\ P(\theta=0)=0.999$。
观测随机变量(检测结果)$X$:$X=1$ 阳性,$X=0$ 阴性。
要求的是后验 $P(\theta=1\mid X=1)$。
表 11.1 先验与似然一览
$\theta$ 先验 $P(\theta)$ $L=P(X=0\mid\theta)$ $L=P(X=1\mid\theta)$
$\theta=0$(健康) $0.999$ $0.98$ $0.02$ $\theta=1$(患病) $0.001$ $0.05$ $0.95$
11.2 套用贝叶斯定理
$$ P(\theta=1\mid X=1)=\frac{P(X=1\mid\theta=1)\,P(\theta=1)}{P(X=1\mid\theta=1)P(\theta=1)+P(X=1\mid\theta=0)P(\theta=0)}. \tag{11.1}$$
$$ =\frac{0.95\times0.001}{0.95\times0.001+0.02\times0.999}=\frac{0.00095}{0.00095+0.01998}\approx\boxed{0.045}. \tag{11.2}$$
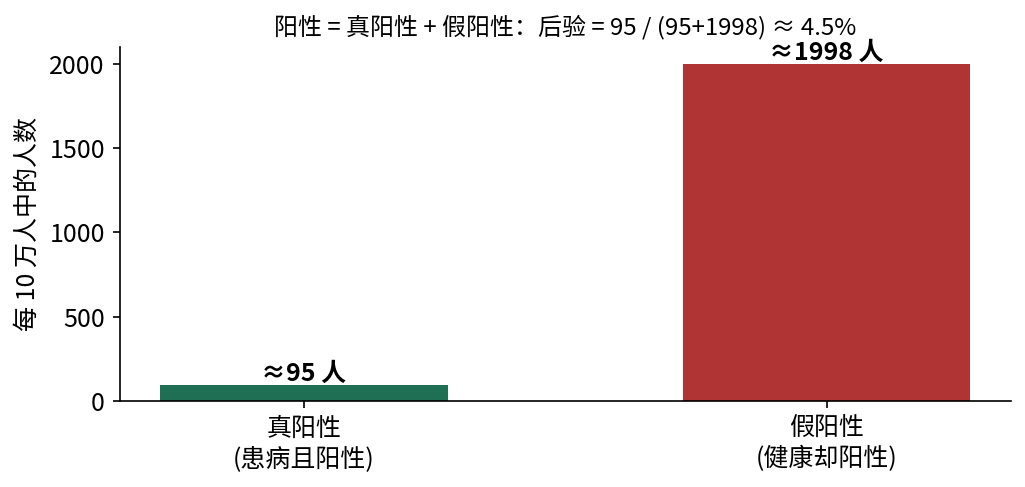
⚠ 反直觉结论
检测灵敏度高达 95%、特异度 98%,可一旦阳性,真患病的概率却只有约 4.5% !换句话说,阳性者里约 95% 为假阳性 (虚惊一场)。
11.3 为什么?——基率谬误(Base-Rate Fallacy)
症结在患病率太低 。阳性只有两个来源:
真患病且检出 :$0.001\times0.95=0.00095$;健康却假阳性 :$0.999\times0.02=0.01998$。
虽然单个健康人假阳性的概率只有 2%,但健康人基数极大 (占 99.9%),这一项乘起来反而远大于 真患病项。于是分母被假阳性主导,后验被压得很低。
图 11.1 基率谬误的直观来源(每 10 万人)。真患病者中检出的真阳性 约 $0.95\times100=95$ 人;健康者中误检的假阳性 约 $0.02\times99\,900\approx1998$ 人。后者因健康人基数巨大而压倒性地多 ,于是阳性者真患病的概率仅 $95/(95+1998)\approx4.5\%$。
◆ 改变患病率会怎样
若患病率 $=50\%$(如某地大流行),则 $P(\theta=1\mid X=1)=\dfrac{0.95\times0.5}{0.95\times0.5+0.02\times0.5}\approx0.979$——这时检测非常可信。
若把患病率再降 10 倍到 $0.0002$,后验会更低。可见同一个检测工具,在不同流行度下「可信度」天差地别 。
结论:脱离「人群基率」单谈「检测多准」,是没有意义的。检测在该病确实在流行 时才有判别价值。
11.4 对可靠性工程的警示
◆ 把「检测试剂」换成「系统可靠性检测工具」
把 HIV 检测换成某种故障检测 / 系统可靠性检测工具 ,结论同样成立:一个号称很准的故障检测器,若目标故障本身极其罕见,那么「报警为真」的概率可能低得惊人。这正是为什么——
不可以单点地相信一个结论。要看可信区间 、要看不确定性 、还要看它整体发生的概率(基率) ,三者综合,才能判断这个工具/结论究竟靠不靠谱。
—— 同理可审视「号称稳赚」的理财宣传:应先考察全行业长期的真实收益基率
▶ Bonus 作业(选做)
自拟一个类似问题并求解;进一步分析灵敏度、特异度、患病率(prevalence) 与最终「阳性者真患病率」之间的关系——可画成一张矩阵 / 表格或一条随患病率从 0 到 1 变化的曲线,直观感受基率的支配作用。
◆ 本章要点
HIV 例:95% 灵敏 + 98% 特异 + 0.1% 患病率 ⇒ 阳性真患病概率仅 ≈ 4.5%。
根因是基率谬误:罕见事件下,假阳性因健康人基数巨大而主导分母。
可靠性启示:评估检测工具必须结合基率,并辅以可信区间与不确定性,拒绝单点轻信。
IV
PART FOUR
第四部分 贝叶斯分类器与网络
Bayesian Classifiers and Networks
朴素贝叶斯分类器,共轭先验,挑战者号案例,贝叶斯网络。
第 12 章 贝叶斯分类与朴素贝叶斯分类器 条件独立假设 第 13 章 可靠性案例:挑战者号 O 型圈 完整推理链 第 14 章 共轭先验:共轭族与可靠性应用 从一对到一族 第 15 章 贝叶斯网络:因果网络、d-分离与链式法则 紧凑表示 第 16 章 贝叶斯网络的可靠性工程应用 人因 · 诊断 · 风险
第 12 章 贝叶斯分类与朴素贝叶斯分类器从「一个特征」到「特征向量」,用一个朴素假设让计算变得可行
前面的诊断都只有一个 观测变量(闻到焦味、检测阳性)。但真实问题里,判断往往依赖一组特征 :判断一封邮件是否垃圾、判断一个人是男是女、判断一台设备处于哪种故障模式。本章把贝叶斯推断推广到特征向量,并引入朴素贝叶斯分类器(NBC) 。
12.1 分类即模式识别
设有 $n$ 个类别,$\theta_i$ 表示第 $i$ 类,$x$ 是观测(特征)。分类就是比较各类的后验 ,取最大者:
$$ P(\theta_i\mid x)=\frac{P(x\mid\theta_i)\,P(\theta_i)}{\sum_{j=1}^{n}P(x\mid\theta_j)P(\theta_j)}=\frac{P(x\mid\theta_i)\,P(\theta_i)}{P(x)}. \tag{12.1}$$
$$ \hat\theta=\arg\max_{\theta_i}P(\theta_i\mid x)\;\propto\;\arg\max_{\theta_i}\,P(x\mid\theta_i)\,P(\theta_i). \tag{12.2}$$
各项含义:$P(\theta_i)$ 是类 $i$ 的先验 (如「中大男女比例」);$P(x\mid\theta_i)$ 是似然 ;$P(x)$ 是与类别无关的归一化常数 (求 $\arg\max$ 时可略去);$P(\theta_i\mid x)$ 是后验 。这是一种判别式 用法:得到各类概率后看谁大。
12.2 难题:联合分布估不动
当 $x$ 是 $D$ 维特征向量 $X=[X^1,X^2,\dots,X^D]^{T}$,每个 $X^j\in\{1,2,\dots,K\}$ 时,似然是一个联合分布 :
$$ P(X=x\mid\Theta=i)=P(X^1=x^1,\dots,X^D=x^D\mid\theta=i). \tag{12.3}$$
⚠ 维度灾难:数据永远不够
要直接估这个联合分布,需要为每一种特征组合 都备足样本。$D=10$ 个二值特征就有 $2^{10}=1024$ 种组合——哪怕每人答案都不同,也得 1024 人才能把组合走一遍;要看出统计规律,十万人都不够。结果是数据极度稀疏 (低秩),联合分布根本估不准。
12.3 朴素假设:条件独立
◆ 朴素贝叶斯的核心假设
假设给定类别后,各特征条件独立 。于是联合似然变成各特征似然之积——加法(组合爆炸)变成乘法 :
$$ P(X=x\mid\Theta=i)=\prod_{j=1}^{D}P(X^j=x^j\mid\theta=i). \tag{12.4}$$
代入 (12.1)、(12.2) 得 NBC 的判决式:
$$ P(\theta_i\mid x)=\frac{\prod_{j=1}^{D}P(X^j=x^j\mid\theta=i)\,P(\theta_i)}{P(x)},\qquad
\hat\theta=\arg\max_{\theta_i}\Big(P(\theta_i)\prod_{j=1}^{D}P(X^j=x^j\mid\theta=i)\Big). \tag{12.5}$$
◆ 条件独立假设的代价与收益
采样成本骤降 :不再需要为 $K^D$ 种组合备数据,只要分别估出每个特征的边缘条件概率即可。一个特征统计上千人就稳定了。代价是一个很强、常常不成立 的假设(经常打游戏的人往往也常点外卖,二者并不独立)。但奇妙的是——即便假设被违背,NBC 往往仍给出相当好的结果 。这正是它的魅力,也是垃圾邮件过滤等任务长期采用它的原因。
12.4 NBC 的训练:基于频次计数
给定训练集 $T=\{(x_1,\theta_1),\dots,(x_N,\theta_N)\}$,其中 $x_i=(x_i^1,\dots,x_i^D)'$,类别 $\theta_i\in\{c_1,\dots,c_n\}$。训练就是统计频次($\mathrm{I}(\cdot)$ 为示性函数):
◆ 先验与似然的极大似然估计
$$ P(\Theta=c_m)=\frac{\sum_{i=1}^{N}\mathrm{I}(\theta_i=c_m)}{N}, \tag{12.6}$$
$$ P(X^j=a_{jl}\mid\Theta=c_m)=\frac{\sum_{i=1}^{N}\mathrm{I}(x_i^{j}=a_{jl},\,\theta_i=c_m)}{\sum_{i=1}^{N}\mathrm{I}(\theta_i=c_m)}. \tag{12.7}$$
先验=某类样本占总样本的比例(统计各类别频次);似然=该类中某特征取某值的比例(统计类内特征频次)。
12.5 完整算例:用 NBC 判 x = (2, M)
训练集共 12 个样本,两个特征 $x^1\in\{1,2,3\}$、$x^2\in\{L,M,H\}$,类别 $\Theta\in\{-1,+1\}$(可类比「男 / 女」或「正常邮件 / 垃圾邮件」):
表 12.1 NBC 训练样本(12 条)
# 1 2 3 4 5 6 7 8 9 10 11 12
$x^1$ 1 1 1 1 2 2 2 2 3 3 3 3 $x^2$ L H H M L L H M H L M M $\Theta$ -1 -1 1 1 1 1 -1 -1 -1 1 1 1
第一步 · 先验 (数类别)。$\Theta=1$ 有 7 个、$\Theta=-1$ 有 5 个:
$$ P(\Theta=1)=\tfrac{7}{12},\qquad P(\Theta=-1)=\tfrac{5}{12}. $$
第二步 · 似然 (在各类内数特征)。我们只需要测试点 $x=(2,M)$ 用到的几项:
$$ P(X^1{=}2\mid\Theta{=}1)=\tfrac{2}{7},\quad P(X^2{=}M\mid\Theta{=}1)=\tfrac{3}{7};\qquad
P(X^1{=}2\mid\Theta{=}{-}1)=\tfrac{2}{5},\quad P(X^2{=}M\mid\Theta{=}{-}1)=\tfrac{1}{5}. $$
第三步 · 比较后验 (分母 $P(x)$ 相同,只比分子):
$$ P(\Theta{=}1)\,P(X^1{=}2\mid\Theta{=}1)\,P(X^2{=}M\mid\Theta{=}1)=\tfrac{7}{12}\times\tfrac{2}{7}\times\tfrac{3}{7}=\tfrac{1}{14}\approx0.0714, \tag{12.8}$$
$$ P(\Theta{=}{-}1)\,P(X^1{=}2\mid\Theta{=}{-}1)\,P(X^2{=}M\mid\Theta{=}{-}1)=\tfrac{5}{12}\times\tfrac{2}{5}\times\tfrac{1}{5}=\tfrac{1}{30}\approx0.0333. \tag{12.9}$$
因为 $\tfrac{1}{14}>\tfrac{1}{30}$,判为 $\hat\theta=+1$ 。归一化后置信度约为
$$ P(\Theta{=}1\mid x)=\frac{1/14}{1/14+1/30}\approx0.68,\qquad P(\Theta{=}{-}1\mid x)\approx0.32. $$
◆ 结果可信吗?两点深入解读
用差距衡量可信度 :$0.68$ vs $0.32$ 差距明显,结论较可信。若归一化后是 $\tfrac{9}{17}$ vs $\tfrac{8}{17}$ 这种接近的情形,说明该样本行为模糊、结论可疑——这就是不确定性量化 。一个耐人寻味的反例 :训练集中恰好出现过一次 $(2,M)$(第 8 号样本),它的真实标签是 $-1$;但 NBC 却判成 $+1$。这说明:某些情况下单条样本并不能代表整体规律;也可能是条件独立假设 带来的偏差,或该点本身即为异常值(outlier) 。这提示个案判断需结合更多信息,单一规则未必可靠。
▶ 现实回响
同一套机制支撑着垃圾邮件过滤 (统计高频词在 spam / 正常邮件中的条件概率)与推荐系统 (网易云音乐并非「你听了 A 就推 A」,而是找到与你相似的人群、用上百个特征聚类后再推荐)。Bonus 作业:到 B 站搜「朴素贝叶斯 + 垃圾邮件检测」看一个实现。
◆ 本章要点
分类=比较各类后验 (12.1);$\arg\max$ 时分母可略。
联合似然因维度灾难估不动;朴素假设(条件独立)把它化为乘积 (12.4),采样成本骤降。
训练靠数频次 (12.6)–(12.7);$x=(2,M)$ 算例:$\tfrac{1}{14}>\tfrac{1}{30}\Rightarrow$ 判 $+1$,置信度约 0.68。
第 13 章 可靠性案例:挑战者号 O 型圈灾难把贝叶斯一步步搭起来——从温度到失效概率的完整推理链
这是本课程的压轴可靠性实案 ,也是把前面所有要素(先验、似然、伯努利分布、Logistic 函数、后验抽样、可信区间)组装成一条完整推理链的范例。它来自经典读物 Bayesian Methods for Hackers 。
13.1 背景
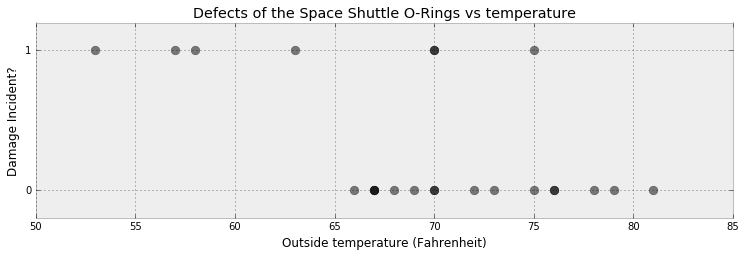
1986 年 1 月 28 日,挑战者号航天飞机升空不久,一个火箭推进器发生爆炸,机上 7 名成员全部遇难。官方结论:事故起因是推进器上的 O 型密封圈 存在缺陷,这种缺陷源于不合理的设计,使 O 型圈对包括外界温度 在内的诸多因素极其敏感。
数据显示:此前的飞行中大量出现过 O 型圈缺陷;但发射前夜的讨论只重视了少数几次 有明确损伤的飞行,其余被认为「没有显著趋势」。问题恰恰在于:温度与事故之间没有一个清晰的「转折点」,量化分析的缺失,让这一本可避免的风险没有被充分暴露。
图 13.1 历史飞行中 O 型圈是否出现缺陷(纵轴 0/1)对外界温度(横轴,华氏度)的散点。可见温度越低,缺陷($=1$)越密集——但二者间没有一刀切的阈值 。数据从约 53°F 起才有记录,而发射当天温度远低于此。
核心问题 :在温度 $t$ 时,事故发生的概率 $p(t)$ 是如何变化的?
13.2 建模四步:把先验知识逐层注入
设计温度相关函数 $p(t)\in[0,1]$。
从数据趋势看,温度升高时缺陷概率 $p(t)$ 应由 1 向 0 变化。选用 Logistic 函数(逻辑斯蒂函数) (logistic function )——其取值天然落在 $[0,1]$,恰好可解释为概率:
$$ p(t)=\frac{1}{1+e^{\beta t}}. \tag{13.1}$$
增加偏置项 $\alpha$。
纯逻辑函数关于原点对称、无法左右平移。加一个偏置 $\alpha$,让曲线能左偏 / 右偏,从而更准确地刻画 $p(t)$ 与温度的关系:
$$ p(t)=\frac{1}{1+e^{\beta t+\alpha}}. \tag{13.2}$$
这里约定 $\beta>0$:温度 $t$ 越高,$e^{\beta t+\alpha}$ 越大,$p(t)$ 越接近 0,即「温度越高、缺陷概率越低」,与散点趋势一致;偏置 $\alpha$ 则决定曲线沿温度轴左右平移的位置。$\alpha,\beta$ 正是下一步要由数据估计的未知参数。
用伯努利分布连接「概率」与「事件」。
把每次飞行「是否出现缺陷」的事件 $D_i$ 设为伯努利随机变量 (Bernoulli ,成功取 1、失败取 0),其参数正是该温度下的缺陷概率:
$$ D_i\sim \mathrm{Ber}\big(p(t_i)\big). \tag{13.3}$$
这与抛硬币完全同构——$p(t_i)$ 就是「这枚(随温度而变的)硬币」正面朝上的概率。
设先验、做后验更新。
最朴素的先验:认为各温度下缺陷概率 $p(t_i)=0.5$,对应参数
$$ \alpha=\beta=0. \tag{13.4}$$
再用历史观测数据,对 $(\alpha,\beta)$ 做后验抽样 ,得到它们的后验分布。
◆ 该建模链的特点:先验可替换
整条链是 温度 $t$ → 概率 $p(t)$ → 缺陷事件 $D_i$ 的完整推理。每一环的「先验」都可以替换成你更相信的形式:你若认为 $p(t)$ 不该用带偏置的逻辑函数,可改用威布尔、伽马 等;你若觉得伯努利不合适,也可另选。把各种历史认知 / 设计手册知识注入进来——这正是用贝叶斯的好处。
13.3 结果与判读
基于后验抽样,取均值得到 $p(t)$ 的估计,并计算其可信区间 (credible interval ——贝叶斯框架下由后验分布直接得到的区间,与频率学派的「置信区间」含义不同):
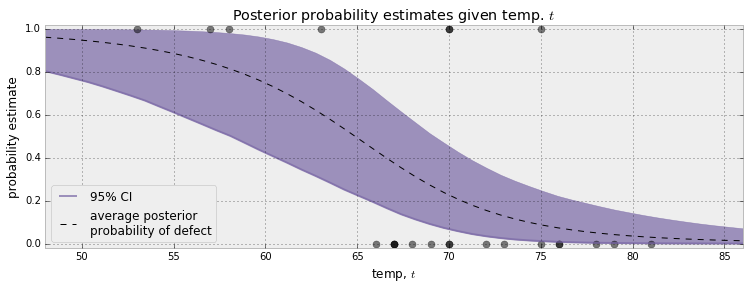
图 13.2 缺陷概率的后验估计随温度 $t$ 的变化:虚线为平均后验概率 ,阴影带为 95% 可信区间 。温度越低,缺陷概率越接近 1;且区间越窄(可信度越高) 。
⚠ 致命的那一天
挑战者号发射当天,外界温度为 31 华氏度 (约 −0.5℃)——远在历史数据左端之外。从后验曲线看,此温度下 O 型圈出现缺陷几乎是必然 :平均后验概率接近 1,且可信区间很窄 (可信度高)。区间窄意味着可信度高,区间宽则可信度低。若当年做过这样一次量化分析,结论本应是清晰而刺目的。
▶ 期末作业(最简单的一次)
换一个不同的先验 (以及 / 或不同的似然),把挑战者号这个案例重做一遍,比较结果。延伸:参考《Bayesian Methods for Hackers》电子版。可借助 AI 工具写代码,全程不过几十行。
◆ 本章要点
建模四步:Logistic 函数 $p(t)=\frac{1}{1+e^{\beta t}}$(约定 $\beta>0$)→ 加偏置 $\frac{1}{1+e^{\beta t+\alpha}}$ → 伯努利 $D_i\sim\mathrm{Ber}(p(t_i))$ → 先验 $\alpha=\beta=0$ 后验抽样。
完整链路:温度 → 失效概率 → 失效事件,每环先验皆可替换为领域知识。
31°F 下缺陷近乎必然且可信区间窄;量化分析的缺失是悲剧可避免却未避免的关键。
第 14 章 共轭先验:共轭族与可靠性应用把第 6 章的发现系统化,并落到可靠性工程
第 6 章我们从一枚硬币出发,亲手推导出「Beta 是二项的共轭先验」,并把共轭理解为一种让贝叶斯计算落地的工程化技巧。本章把视角系统化 :先重新审视先验、似然、后验三者的关系,再给出常用共轭族的对照表,最后落到可靠性工程的具体场景。
14.1 重新审视先验 / 似然 / 后验的关系
回到贝叶斯定理。把事件 $B_i$ 写成连续参数 $\theta$,分母由求和变积分:
$$ P(\theta\mid x)=\frac{P(x\mid\theta)\,P(\theta)}{\displaystyle\int P(x\mid\theta)\,P(\theta)\,d\theta}\;\propto\;P(x\mid\theta)\times P(\theta). \tag{14.1}$$
◆ 一个常被忽视的视角:似然是「关于 θ」的函数
同一个表达式 $P(x\mid\theta)$,看成「关于 $x$ 的函数」时是概率分布 (对 $x$ 归一),看成「关于 $\theta$ 的函数」时则是似然 (对 $\theta$ 不必归一)。式 (14.1) 的分母 $\int P(x\mid\theta)P(\theta)\,d\theta$ 把 $\theta$ 积掉,结果不含 $\theta$ ,故它对后验的「形状」只起归一化作用——这正是第 6 章推导中「上下常数相消、分母不必硬算」的根据,也是求众数 / 比大小时分母总能略去的原因。
正是凭着这一视角,第 6 章才能一眼认出后验分子 $\theta^{\,y+a-1}(1-\theta)^{\,n-y+b-1}$ 就是 Beta 的核,从而直接写出
$$ \text{先验 }\mathrm{Beta}(a,b)\ +\ \text{二项似然}\ \Longrightarrow\ \text{后验 }\mathrm{Beta}(a+y,\,b+n-y). \tag{14.2}$$
14.2 常用共轭族对照表
Beta–二项 只是最先遇到的一组。下表列出几组常用共轭对——它们各自匹配一类数据模型(更完整的列表可查 Wikipedia「Conjugate prior」):
表 14.1 常见的似然 — 共轭先验(后验同族)对照
似然 Likelihood 共轭先验(亦即后验所属族)
伯努利 / 二项 / 负二项 Bernoulli / Binomial / Neg. Binomial Beta 泊松 Poisson Gamma 正态(估均值)Normal(mean) Normal 正态(估精度)Normal(precision) Gamma 正态(估方差)Normal(variance) Inverse Gamma 多元正态 Multivariate Normal Multivariate Normal 均匀 Uniform Pareto 指数 / 威布尔(形状已知)Exponential / Weibull Gamma / Inverse Gamma
实践中 Normal 似然 最常见(高斯是最常用的分布),其共轭先验可选 Normal / Gamma / Inverse Gamma,选择较为灵活。设计模型时优先选用共轭组合,可保证后验有闭式、并支持无限递推更新(详见第 6 章)。
14.3 共轭在可靠性工程中的应用
把共轭对用到可靠性建模、保修分析、失效模式分析、维修策略优化、故障预测与健康管理(PHM)、质量控制、结构健康监测等场景:
表 14.2 可靠性中的典型共轭对
共轭对 应用示例
Beta–Binomial 保修成本分析、缺陷率监测 Gamma–Poisson 维修优化中的故障率建模 Gamma–Exponential 疲劳寿命预测、剩余寿命(RUL)估计 Dirichlet–Multinomial 多状态系统可靠性分析(如供应链网络)
▶ 例子:Gamma–Poisson 与「计数型」可靠性
单位时间内:路口通过的车辆数、产品失效的次数、就诊的病人数——都服从泊松分布 。其速率参数 $\lambda$ 的共轭先验是 Gamma 。于是「故障率建模」可用 Gamma–Poisson 做闭式的贝叶斯更新:每观测一段时间的失效计数,就把 Gamma 的参数更新一次,与第 6 章 Beta 的「参数加法」如出一辙。
挑战者号案例(第 13 章)也可由此重做:它的先验 / 似然有多种合理选择——这正是该案例期末作业的探索空间。
◆ 本章要点
「似然是关于 $\theta$ 的函数」这一视角解释了为何分母(归一化常数)总能略去——也是第 6 章推导的根据。
共轭族不止 Beta–二项一对:Poisson–Gamma、Normal–Normal 等各匹配一类数据模型;Normal 似然最常见。
可靠性常用:Beta–Binomial(缺陷率)、Gamma–Poisson(故障率)、Gamma–Exponential(RUL)、Dirichlet–Multinomial(多状态系统)。
第 15 章 贝叶斯网络:因果网络、d-分离与链式法则当变量很多、彼此牵连时,如何紧凑地表示与推理
前面的贝叶斯都在少数几个变量间打转。现实系统却由大量相互关联的变量 构成。贝叶斯网络 (Bayesian Network )用「节点 + 有向边」把变量间的因果/关联结构画出来,从而紧凑地 表示联合分布并做推理——这是连接「贝叶斯」与「复杂可靠性系统」的桥梁。
15.1 因果网络与几个直觉例子
因果网络由一组变量 与一组连接它们的有向弧 构成,用来推断「一个变量的确定性变化如何影响其它变量」。课堂上的几个经典小例子:
恶心 Nausea :流感 $F$、沙门氏菌 $S$ 都可能导致恶心 $N$。结冰路面 Icy Road :路面结冰 $I$ 可能同时导致 Holmes 出车祸 $H$、Watson 出车祸 $W$。降雨 Rainfall :降雨 $R$ → 水位 $W$ → 洪水 $F$(串行)。湿草坪 Wet Grass :是否有云 → 是否开洒水器 / 是否下雨 → 草坪是否变湿。
15.2 三种连接与证据传递
证据能否沿一条路径传递,取决于中间节点的连接类型和它是否被「实例化」(即取值已知 / 被观测):
A
B
C
B
A
C
A
B
E
串行 Serial
发散 Diverging
汇聚 Converging
图 15.1 三种连接。串行 $A\to B\to C$ 与发散 $A\leftarrow B\to C$:除非中间变量被实例化,证据可传递;汇聚 $A\to E\leftarrow B$:只有当汇聚变量 $E$ 或其后代收到证据时,证据才可在 $A,B$ 间传递。
◆ 证据传递规则
串行连接 :除非连接中间的变量已知 ,证据可由一端传到另一端。发散连接 :除非中间变量被实例化 ,证据可经它传递。汇聚连接 :仅当 该汇聚变量或其某个后代收到证据 时,证据才可经它传递。
15.3 贝叶斯网络的定义
◆ 贝叶斯网络
一组变量 与变量间的一组有向边 ;
每个变量取值于一个有限、互斥 的状态集;
变量与有向边共同构成一个有向无环图(DAG) :不存在有向回路 $A_1\to A_2\to\cdots\to A_n$ 使 $A_1=A_n$;
每个带父节点的变量 $A$(父集 $B_1,\dots,B_n$)都附有一张条件概率表 $P(A\mid B_1,\dots,B_n)$ 。
15.4 d-分离(d-separation)
◆ 定义
因果网络中两个不同变量 $A$、$B$ 称为 d-分离 ,若它们之间所有 路径上都存在一个中间变量 $V$(异于 $A,B$),使得:
连接是串行或发散 ,且 $V$ 已被实例化 ;或
连接是汇聚 ,且 $V$ 及其所有后代都未 收到证据。
若 $A,B$ 不是 d-分离,则称它们 d-连接 。d-分离 ⇔ 给定证据下二者条件独立 。
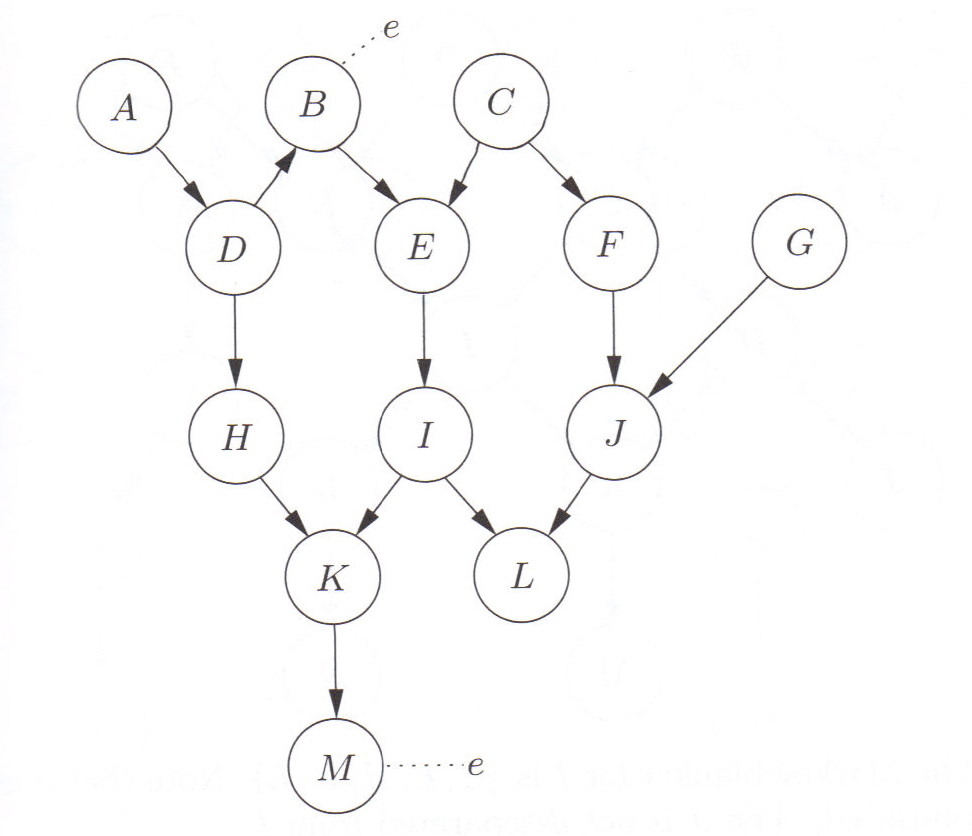
图 15.2 d-分离示例。无证据时,$D,B,E,C,F$ 都与 $A$ d-连接 ;一旦观测到 $B$ ,则 $E,C,F$ 与 $A$ 变为 d-分离 ($B$ 阻断了经它的串行/发散路径)。图中 $B$、$M$ 处标注的 $e$ 表示该节点收到了证据。
15.5 链式法则:紧凑表示联合分布
贝叶斯网络最大的价值在于紧凑表示 :联合分布等于每个变量「在其父节点条件下」的概率之积。
◆ 贝叶斯网络的链式法则
$$ P(U)=\prod_{v\in U} P\big(v \mid \mathrm{parents}(v)\big). \tag{15.1}$$
它是一般链式法则 $P(A_1,\dots,A_n)=\prod_{k}P(A_k\mid A_1,\dots,A_{k-1})$ 在 DAG 结构下的简化:若 $A$ 与 $B$ 在给定 $C$ 时 d-分离,则 $A,B$ 在给定 $C$ 时独立 ,许多条件项因此可以省去。这使得指数级的联合概率表被压缩成若干张小的条件概率表。
15.6 范例:湿草坪网络
Cloud 云
Sprinkler 洒水器
Rain 雨
WetGrass 湿草坪
图 15.3 湿草坪贝叶斯网络。云影响「是否开洒水器」与「是否下雨」;后两者共同决定草坪是否变湿——一个典型的汇聚 结构。
各节点的条件概率表($T$=真,$F$=假):
表 15.1 湿草坪网络的条件概率
节点 条件概率
Cloud $P(C{=}T)=0.5,\quad P(C{=}F)=0.5$ Sprinkler | Cloud $P(S{=}T\mid C{=}F)=0.5,\quad P(S{=}T\mid C{=}T)=0.1$ Rain | Cloud $P(R{=}T\mid C{=}F)=0.2,\quad P(R{=}T\mid C{=}T)=0.8$ WetGrass | S, R $P(W{=}T\mid S{=}F,R{=}F)=0,\ \ P(W{=}T\mid S{=}T,R{=}F)=0.9,$
▶ 完整推理:草坪湿了,更可能是洒水器还是下雨?
已知证据 $W{=}T$,求 $P(S{=}T\mid W{=}T)$ 与 $P(R{=}T\mid W{=}T)$。由链式法则,联合分布为
$$ P(C,S,R,W)=P(C)\,P(S\mid C)\,P(R\mid C)\,P(W\mid S,R). $$
第一步 :对 $C$ 边缘化,得到 $S,R$ 的联合分布(注意 $S,R$ 因共同父节点 $C$ 而不独立 ):
$$ P(S,R)=\sum_{C}P(S\mid C)P(R\mid C)P(C)\ \Rightarrow\
\begin{cases}P(S{=}T,R{=}T)=0.5{\cdot}0.2{\cdot}0.5+0.1{\cdot}0.8{\cdot}0.5=0.09\\
P(S{=}T,R{=}F)=0.21,\quad P(S{=}F,R{=}T)=0.41,\quad P(S{=}F,R{=}F)=0.29\end{cases} $$
第二步 :用 $W$ 的 CPT 算证据概率 $P(W{=}T)$ 及两个联合概率:
$$ P(W{=}T)=0.99{\cdot}0.09+0.9{\cdot}0.21+0.9{\cdot}0.41+0{\cdot}0.29=0.647. $$
$$ P(S{=}T,W{=}T)=0.99{\cdot}0.09+0.9{\cdot}0.21=0.278,\qquad
P(R{=}T,W{=}T)=0.99{\cdot}0.09+0.9{\cdot}0.41=0.458. $$
第三步 :相除得后验:
$$ P(S{=}T\mid W{=}T)=\frac{0.278}{0.647}\approx 0.43,\qquad
P(R{=}T\mid W{=}T)=\frac{0.458}{0.647}\approx 0.71. $$
结论 :$0.71>0.43$,下雨是更可能的原因 ——因为「有云」会同时抬高下雨概率、压低洒水器概率。若此时进一步获知「确实下雨了」($R{=}T$),洒水器的后验会被进一步拉低:一个原因得到确证后会削弱对其它原因的怀疑,这一现象称为解释消除 (explaining away ),正是汇聚结构的典型推理特征。
15.7 贝叶斯网络的学习
这里的「学习」特指从数据中估计网络的参数(条件概率表 CPT)与结构(DAG) ,比第 4 章泛指的「随新数据更新信念」更为具体。
表 15.2 学习贝叶斯网络的两个层面
学习对象 情形 方法
参数学习 结构已知、数据完整 ML、MAP、贝叶斯估计 结构已知、数据缺失 蒙特卡洛、高斯近似、EM 算法 结构学习 结构未知 基于约束(Constraint-based)、基于评分(Score-based)
真实贝叶斯网络可以非常复杂 (几十上百个节点)。这正是它能承载复杂可靠性系统的原因——下一章给出工程实案。
◆ 本章要点
贝叶斯网络 = DAG + 每个节点的条件概率表;节点状态有限互斥。
三种连接(串行 / 发散 / 汇聚)决定证据能否传递;d-分离 ⇔ 条件独立。
链式法则 $P(U)=\prod_v P(v\mid\mathrm{parents}(v))$ 把指数级联合分布压缩为小的条件概率表。
学习分参数学习(含数据缺失时用 EM)与结构学习(约束 / 评分)。
第 16 章 贝叶斯网络的可靠性工程应用案例从人因可靠性到发动机诊断、无人机风险评估
本章把贝叶斯网络落到四个真实工程方向:人因可靠性 、人机界面评价 、复杂发动机故障诊断 、无人机事故风险评估 。它们共同说明:当系统复杂、变量众多、因果交织时,贝叶斯网络是把「机理知识 + 数据」融合起来做诊断与预测的有力工具。
16.1 案例一:飞机作战效能评估中人的可靠性
◆ 动机
已有的飞机作战效能研究,几乎没有考虑飞行员在作战飞行中的可靠性 。作战效能分析中涉及的「人」,主要指人的战术技术决策(或经验)对作战过程的影响——这属于推理决策事件 。而作为飞机作战单元主体的飞行员,能否正确执行自己的意图、所下决定是否正确 ,直接关系作战成败。这正是贝叶斯网络可建模的「软因果」。
◆ 贝叶斯网络建模
把影响飞行员可靠性的因素拆成若干节点:上游为飞行员状态类节点——疲劳水平 $F$、训练熟练度 $T$、心理负荷 $P$、态势感知 $SA$;中游为两个推理决策事件——决策正确性 $D$ 与 意图执行正确性 $E$ ;二者汇聚到顶层人因可靠度 $R$ 。有向边编码因果:$F,P\to SA\to D$,$T\to E$,$D,E\to R$。每个带父节点的变量配一张条件概率表(CPT),其数值来自飞行模拟器试验数据与飞行专家打分。
疲劳 F
心理负荷 P
熟练度 T
态势感知 SA
决策正确 D
执行正确 E
人因可靠度 R
图 16.1 飞行员人因可靠性贝叶斯网络示意。状态因素 $\to$ 决策/执行事件 $\to$ 顶层可靠度。
给定一次任务的观测证据(如「高心理负荷 + 低态势感知」),即可由链式法则(式 15.1)推出 $R$ 的后验分布,并通过敏感性分析定位最薄弱环节。这正是 15.5 链式法则与 15.7 参数学习在人因可靠性上的直接落地。
16.2 案例二:基于人因可靠性的民机驾驶舱人机界面评价
将民机驾驶舱人机界面的要素,按经典的 SHEL 框架 分为四个方面,并研究飞行员(L)与其余要素之间的关系:
表 16.1 驾驶舱人机界面的四要素与评估关系
要素 含义 与飞行员 L 的关系研究
L(人员) 系统人员(飞行员 / 机组) L–L :飞行员与机组人员之间的信息交流、作业协作S(软件 / 规范) 系统软件、操作规范 L–S :飞行员与机组管理、技术培训及操作规范制度的关系H(硬件) 系统硬件设备 L–H :飞行员与硬件作业设备之间的交互E(环境) 系统环境 L–E :飞行员与驾驶舱作业环境的关系
评估内容即确定为 L–L、L–S、L–H、L–E 之间的关系研究。
◆ 从 SHEL 到贝叶斯网络
把 $L,S,H,E$ 各作为一组节点,$L\text{–}L$、$L\text{–}S$、$L\text{–}H$、$L\text{–}E$ 四类交互各设一个「界面适配度」中间节点,四者汇聚到顶层「驾驶舱人机界面可靠度」节点。条件概率表由两部分填充:① 专家对各交互质量的主观打分(先验 );② 飞行事件 / 模拟试验中的差错率统计(似然 ,可用第 6、14 章的 Beta–二项共轭做在线更新)。评估输出为顶层节点的后验概率分布 ;再通过敏感性分析(改变某一节点证据、观察顶层概率变化)找出对界面可靠度影响最大的薄弱要素。
16.3 案例三:复杂发动机系统的故障诊断
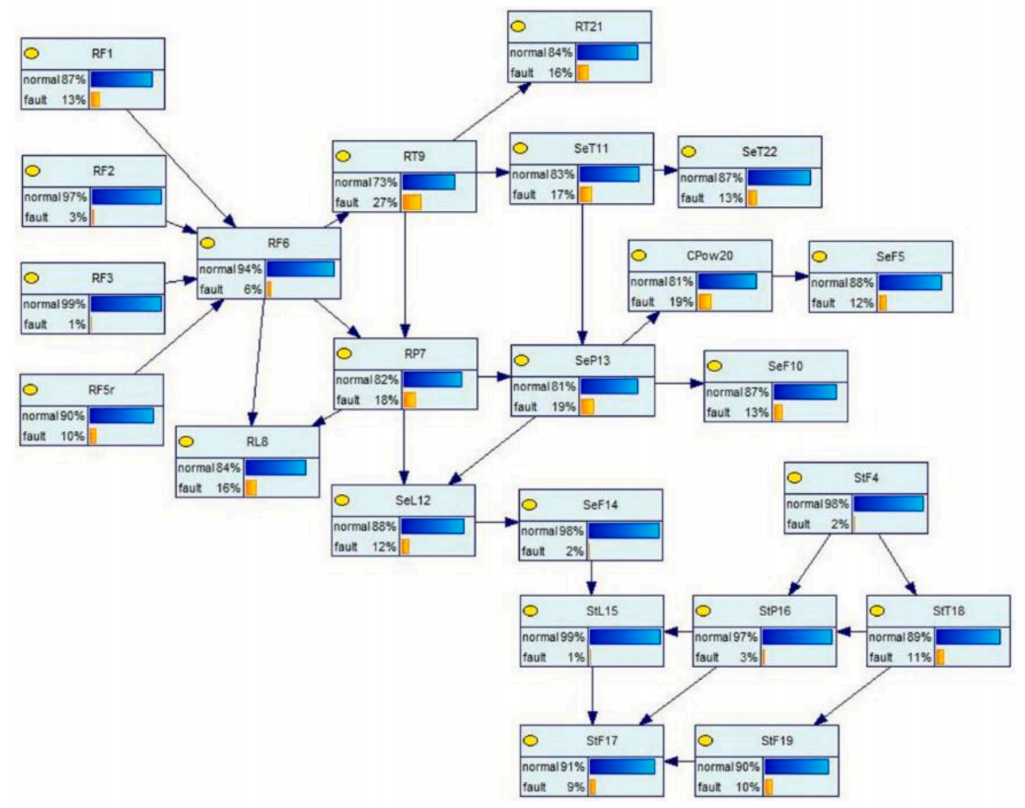
思路是把发动机系统 + 领域知识 转化为贝叶斯网络结构,再用其做故障诊断推理:把观测到的异常征兆(如排气温度升高、振动超标)作为证据节点输入,由链式法则(式 15.1)反向推理各部件故障节点的后验概率,后验最高者即最可能的根因 。
图 16.2 发动机系统及其领域知识——构建贝叶斯网络的物理与机理基础。
图 16.3 据此设计的发动机故障诊断贝叶斯网络。节点对应部件状态 / 观测量,有向边编码机理因果,条件概率表承载诊断知识。
◆ 案例延伸:机理关联 + 过程数据
进一步地,可把机理关联分析 与过程数据 结合,用于诊断「未被监测的根因变量型故障」(即根因没有直接传感器测点的情形)。
Liu N. et al. Fault detection and diagnosis using Bayesian network model combining mechanism correlation analysis and process data: Application to unmonitored root cause variables type faults.
机理 + 数据双驱动的贝叶斯诊断
16.4 案例四:数据驱动贝叶斯网络的无人机事故风险评估
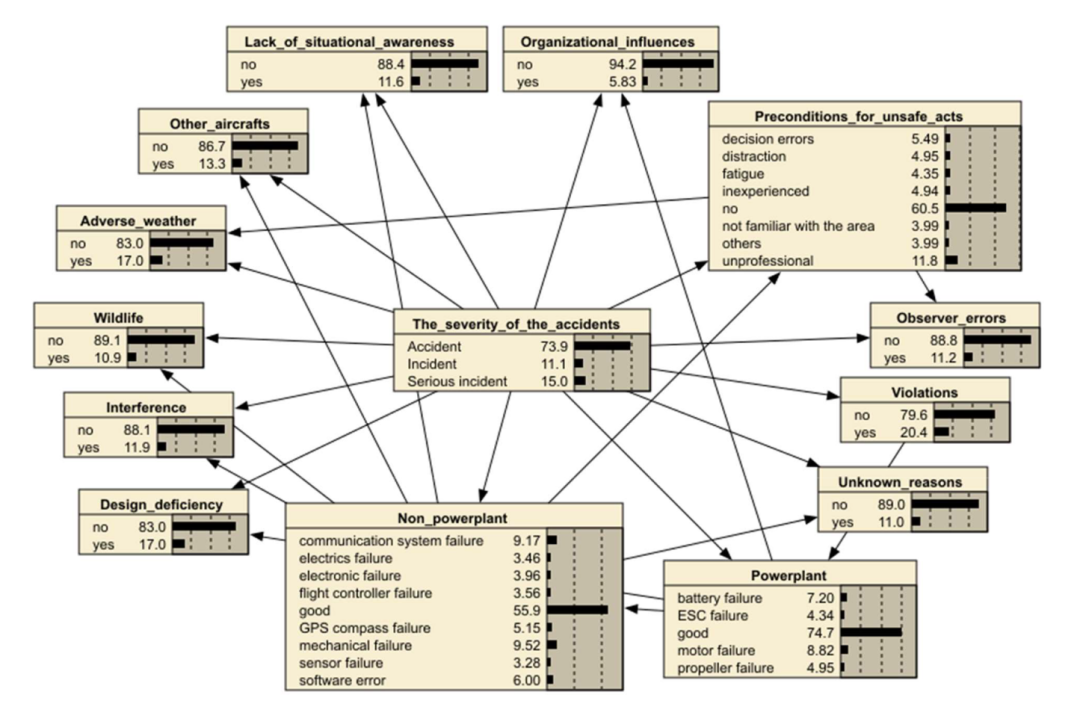
基于无人机事故报告数据集,构建树增强朴素贝叶斯网络(TAN-BN,Tree-Augmented Naive Bayes) 模型。它在朴素贝叶斯的「条件独立」之上,引入树状结构 以允许从数据中加入额外的特征间依赖信息——是第 12 章 NBC 的自然推广。
图 16.4 无人机事故风险的 TAN-BN 模型。数据驱动流程:收集数据 → 用 TAN 算法做结构学习 → 用计数学习算法做参数学习。
◆ 方法流程与验证
结构学习 :TAN 将树状结构引入风险变量,允许从数据中添加额外依赖信息。参数学习 :用 Netica 软件学习每个节点的参数,得到各节点的条件概率表(CPT) ,从而计算每个变量节点的概率。模型验证 :用三种方法——正确性、预测性能、真实案例验证——检验模型有效性。诊断推理 :通过设定节点状态概率,做诊断推理以探索特定事故严重性的成因;把修改后的节点概率作为新证据 输入,即可确定各情形下每种事故严重程度的概率。
SUN X, et al. Risk assessment of unmanned aerial vehicle accidents based on data-driven Bayesian networks. Reliability Engineering & System Safety, 2024, 248: 110185.
数据驱动 TAN-BN 的可靠性风险评估
◆ 本章要点
贝叶斯网络适合刻画可靠性中的「软因果」:人因可靠性、人—机—环(SHEL)界面评价。
复杂系统诊断可由「机理 + 数据」双驱动构建 BN(发动机案例)。
TAN-BN 在 NBC 上引入树结构,数据驱动地做无人机事故风险评估与诊断推理。
附录 作业集、参考文献与联系方式把课堂布置的练习与延伸资料集中于此
A. 作业集
A.1 常规作业
表 A.1 三次常规作业
编号 题目 要点
HW1 诊断检测分析 分析灵敏度 / 特异度 / 患病率(prevalence)三者与「阳性真患病率」的关系(参数分析,见第 11 章) HW2 朴素贝叶斯分类 自定义一个分类问题并用 NBC 求解(见第 12 章) HW3 挑战者号 O 型圈案例重做DDL:2026-06-16 换用不同的先验(及 / 或似然) 把案例重做一遍并比较结果(见第 13、14 章)。可借助 AI 工具写代码,仅需几十行
A.2 Bonus 作业(选做,不计分)
诊断检测延伸 :自拟一个类似 HIV 检测的问题并求解;进一步用矩阵 / 表格或曲线,刻画 sensitivity、specificity、prevalence 与最终检出可信度之间的关系。垃圾邮件 NBC :到 B 站搜索「朴素贝叶斯 + 垃圾邮件检测」,看一个实现,作为课程补充学习。
◆ 作业贯穿的主线能力
三次作业恰好覆盖本讲义三大支柱:HW1 → 推断与基率 (第 11 章)、HW2 → 分类与朴素假设 (第 12 章)、HW3 → 先验设计与共轭 (第 13–14 章)。
B. 参考文献与延伸阅读
Cameron Davidson-Pilon. Bayesian Methods for Hackers: Probabilistic Programming and Bayesian Inference. (挑战者号案例出处;有电子版)
Wikipedia. Conjugate prior. (共轭族对照表更完整的版本,见第 14 章)
Liu N. et al. Fault detection and diagnosis using Bayesian network model combining mechanism correlation analysis and process data: Application to unmonitored root cause variables type faults. (第 16 章 发动机诊断案例)
SUN X, et al. Risk assessment of unmanned aerial vehicle accidents based on data-driven Bayesian networks. Reliability Engineering & System Safety, 2024, 248: 110185.(第 16 章 无人机 TAN-BN 案例)
C. 课程信息
◆ 联系方式
主讲 :冯建设答疑时间(Office Hr) :周二 / 周四下午地点 :理学园东 518
《贝叶斯方法与可靠性工程 · 系列讲义》v1.0 由讲义 PPT、备课及课堂实录整理而成。